Question 1
In order to perform honest assessment on a predictive model, what is an acceptable division
between training, validation, and testing data?
- A. Training: 50% Validation: 0% Testing: 50%
- B. Training: 100% Validation: 0% Testing: 0%
- C. Training: 0% Validation: 100% Testing: 0%
- D. Training: 50% Validation: 50% Testing: 0%
Answer:
D
Comments
Question 2
Refer to the exhibit: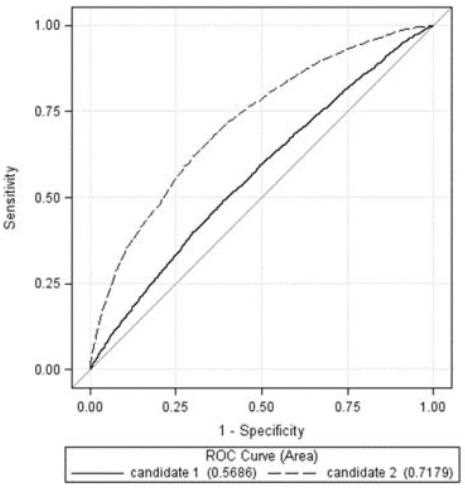
Based upon the comparative ROC plot for two competing models, which is the champion model and
why?
- A. Candidate 1, because the area outside the curve is greater
- B. Candidate 2, because the area under the curve is greater
- C. Candidate 1, because it is closer to the diagonal reference curve
- D. Candidate 2, because it shows less over fit than Candidate 1
Answer:
B
Comments
Question 3
A marketing campaign will send brochures describing an expensive product to a set of customers.
The cost for mailing and production per customer is $50. The company makes $500 revenue for each
sale.
What is the profit matrix for a typical person in the population?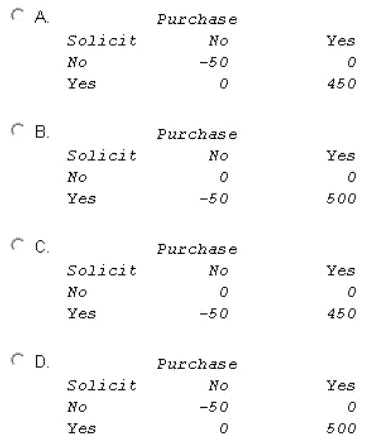
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer:
C
Comments
Question 4
A confusion matrix is created for data that were oversampled due to a rare target.
What values are not affected by this oversampling?
- A. Sensitivity and PV+
- B. Specificity and PV-
- C. PV+ and PV-
- D. Sensitivity and Specificity
Answer:
D
Comments
Question 5
This question will ask you to provide missing code segments.
A logistic regression model was fit on a data set where 40% of the outcomes were events (TARGET=1)
and 60% were non-events (TARGET=0). The analyst knows that the population where the model will
be deployed has 5% events and 95% non-events. The analyst also knows that the company's profit
margin for correctly targeted events is nine times higher than the company's loss for incorrectly
targeted non-event.
Given the following SAS program:
What X and Y values should be added to the program to correctly score the data?
- A. X=40, Y=10
- B. X=.05, Y=10
- C. X=.05, Y=.40
- D. X=.10, Y=05
Answer:
B
Comments
Question 6
An analyst has a sufficient volume of data to perform a 3-way partition of the data into training,
validation, and test sets to perform honest assessment during the model building process.
What is the purpose of the training data set?
- A. To provide an unbiased measure of assessment for the final model.
- B. To compare models and select and fine-tune the final model.
- C. To reduce total sample size to make computations more efficient.
- D. To build the predictive models.
Answer:
A
Comments
Question 7
Refer to the confusion matrix: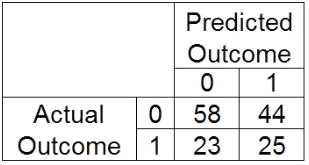
Calculate the sensitivity. (0 - negative outcome, 1 - positive outcome)
Click the calculator button to display a calculator if needed.
- A. 25/48
- B. 58/102
- C. 25/B9
- D. 58/81
Answer:
A
Comments
Question 8
The total modeling data has been split into training, validation, and test data.
What is the best data to use for model assessment?
- A. Training data
- B. Total data
- C. Test data
- D. Validation data
Answer:
D
Comments
Question 9
What is a drawback to performing data cleansing (imputation, transformations, etc.) on raw data
prior to partitioning the data for honest assessment as opposed to performing the data cleansing
after partitioning the data?
- A. It violates assumptions of the model.
- B. It requires extra computational effort and time.
- C. It omits the training (and test) data sets from the benefits of the cleansing methods.
- D. There is no ability to compare the effectiveness of different cleansing methods.
Answer:
D
Comments
Question 10
A company has branch offices in eight regions. Customers within each region are classified as either
"High Value" or "Medium Value" and are coded using the variable name VALUE. In the last year, the
total amount of purchases per customer is used as the response variable.
Suppose there is a significant interaction between REGION and VALUE. What can you conclude?
- A. More high value customers are found in some regions than others.
- B. The difference between average purchases for medium and high value customers depends on the region.
- C. Regions with higher average purchases have more high value customers.
- D. Regions with higher average purchases have more medium value customers.
Answer:
B
Comments
Page 1 out of 9
Viewing questions 1-10 out of 99
page 2