oracle 1z0-1084-21 practice test
Oracle Cloud Infrastructure Developer 2021 Associate Exam
Last exam update: Jul 20 ,2024
Question 1
What can you use to dynamically make Kubernetes resources discoverable to public DNS servers?
- A. ExternalDNS
- B. CoreDNS
- C. DynDNS
- D. kubeDNS
Answer:
A
Explanation:
Setting up ExternalDNS for Oracle Cloud Infrastructure (OCI):
Inspired by
Kubernetes DNS
, Kubernetes' cluster-internal DNS server, ExternalDNS makes Kubernetes
resources discoverable via public DNS servers. Like KubeDNS, it retrieves a list of resources (Services,
Ingresses, etc.) from the
Kubernetes API
to determine a desired list of DNS records.
In a broader sense,ExternalDNSallows you tocontrol DNS records dynamically via Kubernetes
resources in a DNS provider-agnostic way
Deploy ExternalDNS
Connect yourkubectlclient to the cluster you want to test ExternalDNS with. We first need to create
a config file containing the information needed to connect with the OCI API.
Create a new file (oci.yaml) and modify the contents to match the example below. Be sure to adjust
the values to match your own credentials:
auth:
region: us-phoenix-1
tenancy: ocid1.tenancy.oc1...
user: ocid1.user.oc1...
key: |
-----BEGIN RSA PRIVATE KEY-----
-----END RSA PRIVATE KEY-----
fingerprint: af:81:71:8e...
compartment: ocid1.compartment.oc1...
Reference:
https://github.com/kubernetes-sigs/external-dns/blob/master/README.md
https://github.com/kubernetes-sigs/external-dns/blob/master/docs/tutorials/oracle.md
Question 2
You have deployed a Python application on Oracle Cloud Infrastructure Container Engine for
Kubernetes. However, during testing you found a bug that you rectified and created a new Docker
image. You need to make sure that if this new Image doesn't work then you can roll back to the
previous version.
Using kubectl, which deployment strategies should you choose?
- A. Rolling Update
- B. Canary Deployment
- C. Blue/Green Deployment
- D. A/B Testing
Answer:
C
Explanation:
Using Blue-Green Deployment to Reduce Downtime and Risk:
>Blue-green deploymentis a technique thatreduces downtime and risk by running two identical
production environments called Blue and Green. At any time, only one of the environments is live,
with the live environment serving all production traffic. For this example, Blue is currently live and
Green is idle.
This technique can eliminate downtime due to app deployment. In addition, blue-green deployment
reduces risk:if something unexpected happenswith yournew version on Green,you can
immediately roll backto thelast version by switching back to Blue.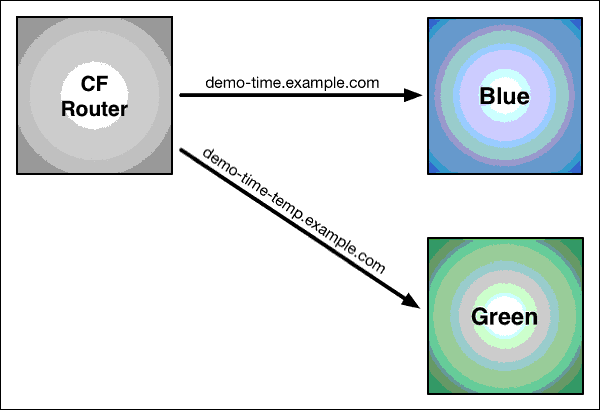
>Canary deploymentsare a pattern for rolling out releases to a subset of users or servers. The idea is
to first deploy the change to a small subset of servers, test it, and then roll the change out to the rest
of the servers. The canary deployment serves as an early warning indicator with less impact on
downtime: if the canary deployment fails, the rest of the servers aren't impacted.
>A/B testingis a way to compare two versions of a single variable, typically by testing a subject's
response to variant A against variant B, and determining which of the two variants is more effective
>Rolling updateoffers a way to deploy the new version of your application gradually across your
cluster.
Reference:
https://docs.cloudfoundry.org/devguide/deploy-apps/blue-green.html
Question 3
What are two of the main reasons you would choose to implement a serverless architecture?
- A. No need for integration testing
- B. Reduced operational cost
- C. Improved In-function state management
- D. Automatic horizontal scaling
- E. Easier to run long-running operations
Answer:
B, D
Explanation:
Serverless computing refers to a concept in which the user does not need to manage any server
infrastructure at all. The user does not run any servers, but instead deploys the application code to a
service providers platform. The application logic is executed,scaled, and billed on demand, without
any costs to the user when the application is idle.
Benefits of the Serverless or FaaS
So far almost every aspect of Serverless or FaaS is discussed in a brief, so lets talk about the pros and
cons of using Serverless or FaaS
Reduced operational and development cost
Serverless or FaaS offers less operational and development cost as it encourages to use third-party
services like Auth, Database and etc.
Scaling
Horizontal scaling in Serverless or FaaS is completely automatic, elastic and managed by FaaS
provider.If your application needs more requests to be processed in parallel the provider will take of
that without you providing any additional configuration.
Reference:
https://medium.com/@avishwakarma/serverless-or-faas-a-deep-dive-e67908ca69d5
https://qvik.com/news/serverless-faas-computing-costs/
https://pages.awscloud.com/rs/112-TZM-766/images/PTNR_gsc-serverless-ebook_Feb-2019.pdf
Question 4
Who is responsible for patching, upgrading and maintaining the worker nodes in Oracle Cloud
Infrastructure Container Engine for Kubernetes (OKE)?
- A. It Is automated
- B. Independent Software Vendors
- C. Oracle Support
- D. The user
Answer:
D
Explanation:
After a new version of Kubernetes has been released and when Container Engine for Kubernetes
supports the new version, you can use Container Engine for Kubernetes to upgrade master nodes
running older versions of Kubernetes. Because Container Engine for Kubernetes distributes the
Kubernetes Control Plane on multiple Oracle-managed master nodes (distributed across different
availability domains in a region where supported) to ensure high availability, you're able to upgrade
the Kubernetes version running on master nodes with zero downtime.
Having upgraded master nodes to a new version of Kubernetes, you can subsequently create new
node pools running the newer version. Alternatively, you can continue to create new node pools that
will run older versions of Kubernetes (providing those older versions are compatible with the
Kubernetes version running on the master nodes).
Note that you upgrade master nodes by performing an in-place upgrade, but you upgrade worker
nodes by performing an out-of-place upgrade. To upgrade the version of Kubernetes running on
worker nodes in a node pool, you replace the original node pool with a new node pool that has new
worker nodes running the appropriate Kubernetes version. Having 'drained' existing worker nodes in
the original node pool to prevent new pods starting and to delete existing pods, you can then delete
the original node pool.
Upgrading the Kubernetes Version on Worker Nodes in a Cluster:
After a new version of Kubernetes has been released and when Container Engine for Kubernetes
supports the new version, you can use Container Engine for Kubernetes to upgrade master nodes
running older versions of Kubernetes. Because Container Engine for Kubernetes distributes the
Kubernetes Control Plane on multiple Oracle-managed master nodes (distributed across different
availability domains in a region where supported) to ensure high availability, you're able to upgrade
the Kubernetes version running on master nodes with zero downtime.
You can upgrade the version of Kubernetes running on the worker nodes in a cluster in two ways:
(A) Perform an 'in-place' upgradeof a node pool in the cluster, by specifying a more recent
Kubernetes version for new worker nodes starting in the existing node pool. First, you modify the
existing node pool's properties to specify the more recent Kubernetes version. Then, you 'drain'
existing worker nodes in the node pool to prevent new pods starting, and to delete existing pods.
Finally, you terminate each of the worker nodes in turn. When new worker nodes are started in the
existing node pool, they run the more recent Kubernetes version you specified. See
Performing an In-
Place Worker Node Upgrade by Updating an Existing Node Pool
.
(B) Perform an 'out-of-place' upgradeof a node pool in the cluster, by replacing the original node
pool with a new node pool. First, you create a new node pool with a more recent Kubernetes version.
Then, you 'drain' existing worker nodes in the original node pool to prevent new pods starting, and to
delete existing pods. Finally, you delete the original node pool. When new worker nodes are started
in the new node pool, they run the more recent Kubernetes version you specified. See
Performing an
Out-of-Place Worker Node Upgrade by Replacing an Existing Node Pool with a New Node Pool
.
Note that in both cases:
The more recent Kubernetes version you specify for the worker nodes in the node pool must be
compatible with the Kubernetes version running on the master nodes in the cluster. See
Upgrading
Clusters to Newer Kubernetes Versions
).
You must drain existing worker nodes in the original node pool. If you don't drain the worker nodes,
workloads running on the cluster are subject to disruption.
Reference:
https://docs.cloud.oracle.com/en-
us/iaas/Content/ContEng/Tasks/contengupgradingk8sworkernode.htm
Question 5
Which two are benefits of distributed systems?
- A. Privacy
- B. Security
- C. Ease of testing
- D. Scalability
- E. Resiliency
Answer:
D, E
Explanation:
distributed systems of native-cloud like functions that have a lot of benefit like
Resiliency and availability
Resiliency and availability refers to the ability of a system to continue operating, despite the failure
or sub-optimal performance of some of its components.
In the case of Oracle Functions:
The control plane is a set of components that manages function definitions.
The data plane is a set of components that executes functions in response to invocation requests.
For resiliency and high availability, both the control plane and data plane components are distributed
across different availability domains and fault domains in a region. If one of the domains ceases to be
available, the components in the remaining domains take over to ensure that function definition
management and execution are not disrupted.
When functions are invoked, they run in the subnets specified for the application to which the
functions belong. For resiliency and high availability, best practice is to specify a regional subnet for
an application (or alternatively, multiple AD-specific subnets in different availability domains). If an
availability domain specified for an application ceases to be available, Oracle Functions runs
functions in an alternative availability domain.
Concurrency and Scalability
Concurrency refers to the ability of a system to run multiple operations in parallel using shared
resources. Scalability refers to the ability of the system to scale capacity (both up and down) to meet
demand.
In the case of Functions, when a function is invoked for the first time, the function's image is run as a
container on an instance in a subnet associated with the application to which the function belongs.
When the function is executing inside the container, the function can read from and write to other
shared resources and services running in the same subnet (for example, Database as a Service). The
function can also read from and write to other shared resources (for example, Object Storage), and
other Oracle Cloud Services.
If Oracle Functions receives multiple calls to a function that is currently executing inside a running
container, Oracle Functions automatically and seamlessly scales horizontally to serve all the incoming
requests. Oracle Functions starts multiple Docker containers, up to the limit specified for your
tenancy. The default limit is 30 GB of RAM reserved for function execution per availability domain,
although you can request an increase to this limit. Provided the limit is not exceeded, there is no
difference in response time (latency) between functions executing on the different containers.
Question 6
You created a pod called "nginx" and its state is set to Pending.
Which command can you run to see the reason why the "nginx" pod is in the pending state?
- A. kubect2 logs pod nginx
- B. kubect2 describe pod nginx
- C. kubect2 get pod nginx
- D. Through the Oracle Cloud Infrastructure Console
Answer:
B
Explanation:
Debugging Pods
The first step in debugging a pod is taking a look at it. Check the current state of the pod and recent
events with the following command:
kubectl describe pods ${POD_NAME}
Look at the state of the containers in the pod. Are they allRunning? Have there been recent restarts?
Continue debugging depending on the state of the pods.
My pod stays pending
If a pod is stuck inPendingit means that it can not be scheduled onto a node. Generally this is
because there are insufficient resources of one type or another that prevent scheduling. Look at the
output of thekubectl describe ...command above. There should be messages from the scheduler
about why it can not schedule your pod.
https://kubernetes.io/docs/tasks/debug-application-cluster/debug-pod-replication-controller/
Question 7
You are tasked with developing an application that requires the use of Oracle Cloud Infrastructure
(OCI) APIs to POST messages to a stream in the OCI Streaming service.
Which statement is incorrect?
- A. The request must include an authorization signing string including (but not limited to) x-content- sha256, content-type, and content-length headers.
- B. The Content-Type header must be Set to application/j son
- C. An HTTP 401 will be returned if the client's clock is skewed more than 5 minutes from the server's.
- D. The request does not require an Authorization header.
Answer:
D
Explanation:
Authorization Header
The Oracle Cloud Infrastructure signature uses the "Signature" Authentication scheme (with
anAuthorizationheader), and not the Signature HTTP header.
Required Credentials and OCIDs
You need an API signing key in the correct format. See
Required Keys and OCIDs
.
You also need the OCIDs for your tenancy and user. See
Where to Get the Tenancy's OCID and User's
OCID
.
Summary of Signing Steps
In general, these are the steps required to sign a request:
Form the HTTPS request (SSL protocol TLS 1.2 is required).
Create the signing string, which is based on parts of the request.
Create the signature from the signing string, using your private key and the RSA-SHA256 algorithm.
Add the resulting signature and other required information to theAuthorizationheader in the
request.
Reference:
https://docs.cloud.oracle.com/en-us/iaas/Content/Streaming/Concepts/streamingoverview.htm
https://docs.cloud.oracle.com/en-us/iaas/Content/API/Concepts/signingrequests.htm
Question 8
You need to execute a script on a remote instance through Oracle Cloud Infrastructure Resource
Manager. Which option can you use?
- A. Use /bin/sh with the full path to the location of the script to execute the script.
- B. It cannot be done.
- C. Download the script to a local desktop and execute the script.
- D. Use remote-exec
Answer:
D
Explanation:
Using Remote Exec
With Resource Manager, you can use
Terraform's remote exec functionality
to execute scripts or
commands on a remote computer. You can also use this technique for other provisioners that require
access to the remote resource.
Reference:
https://docs.cloud.oracle.com/en-us/iaas/Content/ResourceManager/Tasks/usingremoteexec.htm
Question 9
You encounter an unexpected error when invoking the Oracle Function named "myfunction" in
application "myapp". Which can you use to get more information on the error?
- A. fn --debug invoke myapp myfunction
- B. DEBOG=1 fn invoke myapp myfunction
- C. fn --verbose invoke myapp myfunction
- D. Call Oracle support with your error message
Answer:
B
Explanation:
Troubleshooting Oracle Functions
If you encounter an unexpected error when using an Fn Project CLI command, you can find out more
about the problem by starting the command with the stringDEBUG=1and running the command
again. For example:
$ DEBUG=1 fn invoke helloworld-app helloworld-func
Note thatDEBUG=1must appear before the command, and thatDEBUGmust be in upper case.
Question 10
In order to effectively test your cloud-native applications, you might utilize separate environments
(development, testing, staging, production, etc.). Which Oracle Cloud Infrastructure (OC1) service
can you use to create and manage your infrastructure?
- A. Use the Oracle Cloud Infrastructure Console and enter the password in the function configuration section in the provided input field.
- A. OCI Compute
- B. Encrypt the password using Oracle Cloud Infrastructure Key Management. Decrypt this password in your function code with the generated key.
- B. OCI Container Engine for Kubernetes
- C. All function configuration variables are automatically encrypted by Oracle Functions.
- C. OCI Resource Manager
- D. Use Oracle Cloud Infrastructure Key Management to auto-encrypt the password. It will inject the auto-decrypted password inside your function container.
- D. OCI API Gateway
Answer:
C
Explanation:
Resource Manager is an Oracle Cloud Infrastructure service that allows you toautomatethe process
of provisioning your Oracle Cloud Infrastructure resources. Using Terraform, Resource Manager helps
youinstall,configure, andmanageresources through the "infrastructure-as-code" model.
Reference:
https://docs.cloud.oracle.com/iaas/Content/ResourceManager/Concepts/resourcemanager.htm
Question 11
You are developing a serverless application with Oracle Functions and Oracle Cloud Infrastructure
Object Storage- Your function needs to read a JSON file object from an Object Storage bucket named
"input-bucket" in compartment "qa-compartment". Your corporate security standards mandate the
use of Resource Principals for this use case.
Which two statements are needed to implement this use case?
- A. Run oci session authenticate and provide your credentials
- A. Set up a policy with the following statement to grant read access to the bucket: allow dynamic-group read-file-dg to read objects in compartment qa-compartment where target .bucket .name=' input-bucket *
- B. Run oci setup keys and provide your credentials
- B. Set up the following dynamic group for your function's OCID: Name: read-file-dg Rule: resource . id = ' ocid1. f nf unc. ocl -phx. aaaaaaaakeaobctakezj z5i4uj j 7g25q7sx5mvr55pms6f 4da !
- C. Run oci session refresh --profile
- C. Set up a policy to grant all functions read access to the bucket: allow all functions in compartment qa-compartment to read objects in target.bucket.name='input-bucket'
- D. Run oci setup oci-cli-rc --file path/to/target/file
- D. Set up a policy to grant your user account read access to the bucket: allow user XYZ to read objects in compartment qa-compartment where target .bucket, name-'input-bucket'
- E. No policies are needed. By default, every function has read access to Object Storage buckets in the tenancy
Answer:
AB
Explanation:
When a function you've deployed to Oracle Functions is running, it can access other Oracle Cloud
Infrastructure resources. For example:
- You might want a function to get a list of VCNs from the Networking service.
- You might want a function to read data from an Object Storage bucket, perform some operation on
the data, and then write the modified data back to the Object Storage bucket.
To enable a function to access another Oracle Cloud Infrastructure resource, youhave to include the
function in a dynamic group, and then create a policy to grant the dynamic group access to that
resource.
https://docs.cloud.oracle.com/en-
us/iaas/Content/Functions/Tasks/functionsaccessingociresources.htm
Question 12
You are developing a distributed application and you need a call to a path to always return a specific
JSON content deploy an Oracle Cloud Infrastructure API Gateway with the below API deployment
specification.
What is the correct value for type?
- A. iad.ocir.io/myproject/heyoci/myapp:latest
- A. STOCK_RESPONSE_BACKEND
- B. iad.ocir.io/heyoci/myproject/myapp:0.0.1
- B. CONSTANT_BACKEND
- C. us-ashburn-1.ocir.io/heyoci/myproject/myapp:0.0.2-beta
- C. JSON_BACKEND
- D. us-ashburn-1.ocir.io/myproject/heyoci/myapp:latest
- D. HTTP_BACKEND
- E. iad.ocir.io/heyoci/myapp:0.0.2-beta
- F. iad.ocir.io/heyoci/myapp:latest
- G. us-ashburn-1.ocir.io/heyoci/myapp:0.0.2-beta
Answer:
A
Explanation:
Adding Stock Responses as an API Gateway Back End:
You'll often want to verify that an API has been successfully deployed on an API gatewaywithout
having to set up anactual back-end service. One approach is to define a route in the API deployment
specification that has a path to a'dummy' back end. On receiving a request to that path, the API
gateway itself acts as the back endand returns a stockresponse you've specified.
Equally, there are some situations in a production deployment where you'll want a particular path for
a route to consistently return the same stock response without sending a request to a back end. For
example, when you want a call to a path to always return a specific HTTP status code in the response.
Using the API Gateway service, you can define a path to a stock response back end that always
returns the same:
HTTP status code
HTTP header fields (name-value pairs)
content in the body of the response
"type": "STOCK_RESPONSE_BACKEND"indicates that the API gateway itself will act as the back end
and return the stock response you define (the status code, the header fields and the body content).
Reference:
https://docs.cloud.oracle.com/en-
us/iaas/Content/APIGateway/Tasks/apigatewayaddingstockresponses.htm
Question 13
You are developing a serverless application with Oracle Functions. You have created a function in
compartment named prod. When you try to invoke your function you get the following error.
Error invoking function. status: 502 message: dhcp options ocid1.dhcpoptions.oc1.phx.aaaaaaaac...
does not exist or Oracle Functions is not authorized to use it
How can you resolve this error?
- A. kubectl rolling-update
- A. Create a policy: Allow function-family to use virtual-network-family in compartment prod
- B. kubectl update -c
- B. Create a policy: Allow any-user to manage function-family and virtual-network-family in compartment prod
- C. kubectl rolling-update --image=image:v2
- C. Create a policy: Allow service FaaS to use virtual-network-family in compartment prod
- D. kubectl upgrade --image=image:v2
- D. Deleting the function and redeploying it will fix the problem
Answer:
C
Explanation:
Troubleshooting Oracle Functions:
There are common issues related to Oracle Functions and how you can address them.
Invoking a function returns a FunctionInvokeSubnetNotAvailable message anda 502 error (due to a
DHCP Options issue)
When you invoke a function that you've deployed to Oracle Functions, you might see the following
error message:
{"code":"FunctionInvokeSubnetNotAvailable","message":"dhcp options ocid1.dhcpoptions........ does
not exist or Oracle Functions is not authorized to use it"}
Fn: Error invoking function. status: 502 message: dhcp options ocid1.dhcpoptions........ does not exist
or Oracle Functions is not authorized to use it
If you see this error:
Double-check that a policy has been created to give Oracle Functions access to network resources.
Create Policies to Control Access to Network and Function-Related Resources:
Service Access to Network Resources
When Oracle Functions users create a function or application, they have to specify a VCN and a
subnet in which to create them. To enable the Oracle Functions service to create the function or
application in the specified VCN and subnet, you must create an identity policy to grant the Oracle
Functions service access to the compartment to which the network resources belong.
To create a policy to give the Oracle Functions service access to network resources:
Log in to the Console as a tenancy administrator.
Create a new policy in the root compartment:
Open the navigation menu. UnderGovernance and Administration, go toIdentityand clickPolicies.
Follow the instructions in
To create a policy
, and give the policy a name (for example,functions-
service-network-access).
Specify a policy statement to give the Oracle Functions service access to the network resources in the
compartment:
Allow service FaaS to use virtual-network-family in compartment <compartment-name>
For example:
Allow service FaaS to use virtual-network-family in compartment acme-network
ClickCreate.
Double-check that the set of DHCP Options in the VCN specified for the application still exists.
Reference:
https://docs.cloud.oracle.com/en-us/iaas/Content/Functions/Tasks/functionstroubleshooting.htm
https://docs.cloud.oracle.com/en-us/iaas/Content/Functions/Tasks/functionscreatingpolicies.htm
Question 14
What is the minimum of storage that a persistent volume claim can obtain in Oracle Cloud
Infrastructure Container Engine for Kubernetes (OKE)?
- A. Oracle Functions does not allow a microservice deployed on OKE to invoke a function.
- A. 50 GB
- B. OKE does not allow a microservice to invoke a function from Oracle Functions.
- B. 10 GB
- C. Use the OCI CLI with kubectl to invoke the function from the microservice.
- C. 1 GB
- D. Use the OCI Java SDK to invoke the function from the microservice.
- D. 1 TB
Answer:
A
Explanation:
The minimum amount of persistent storage that a PVC can request is 50 gigabytes. If the request is
for less than 50 gigabytes, the request is rounded up to 50 gigabytes.
https://docs.cloud.oracle.com/en-
us/iaas/Content/ContEng/Tasks/contengcreatingpersistentvolumeclaim.htm
Question 15
Which two are characteristics of microservices?
- A. Use OCI Block Volume backed persistent volume.
- A. Microservices are hard to test in isolation.
- B. Use open source storage solutions on top of OCI.
- B. Microservices can be independently deployed.
- C. Use GlusterFS as persistent volume.
- C. All microservices share a data store.
- D. Use OCI Object Storage as persistent volume.
- D. Microservices can be implemented in limited number of programming languages.
- E. Use OCI File Services as persistent volume.
- E. Microservices communicate over lightweight APIs.
Answer:
BE
Explanation:
Learn About the Microservices Architecture
If you want to design an application that is multilanguage, easily scalable, easy to maintain and
deploy, highly available, and that minimizes failures, then use the microservices architecture to
design and deploy a cloud application.
In a microservices architecture, each microservice owns a simple task, and communicates with the
clients or with other microservices byusing lightweight communication mechanisms such as REST
API requests.
The following diagram shows the architecture of an application that consists of multiple
microservices.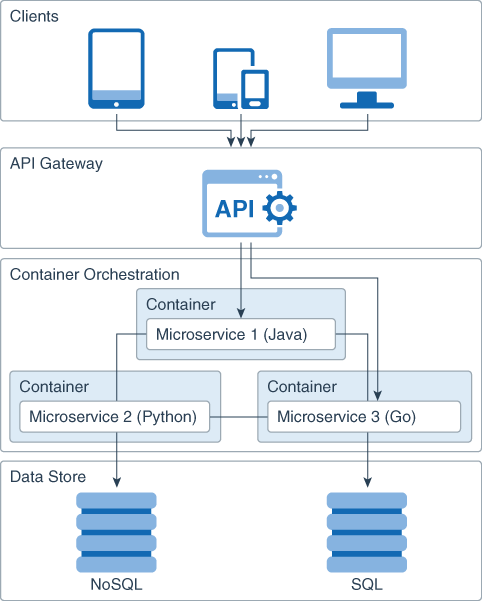
Microservices enable you to design your application as acollection of loosely coupled services.
Microservices follow the share-nothing model, and run as stateless processes. This approach makes it
easier to scale and maintain the application.
The API layer is the entry point for all the client requests to a microservice. The API layer also enables
the microservices to communicate with each other over HTTP, gRPC, and TCP/UDP.
The logic layer focuses on a single business task, minimizing the dependencies on the other
microservices. This layer can be written in a different language for each microservice.
The data store layer provides a persistence mechanism, such as a database storage engine, log files,
and so on. Consider using a separate persistent data store for each microservice.
Typically, each microservice runs in acontainerthat provides alightweight runtime environment.
Loosely coupled with other services- enables a teamto work independentlythe majority of time on
their service(s) without being impacted by changes to other services and without affecting other
services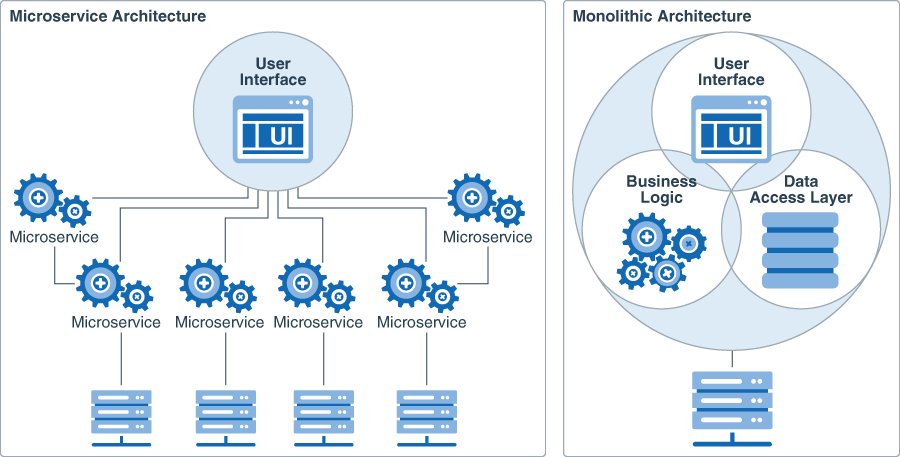
Reference:
https://docs.oracle.com/en/solutions/learn-architect-microservice/index.html
https://microservices.io/patterns/microservices.html
https://www.techjini.com/blog/microservices/