Question 1
Which two statements are true about a self join?
- A. The join key column must have an index.
- B. It can be a left outer join.
- C. It must be a full outer join.
- D. It can be an inner join.
- E. It must be an equijoin.
Answer:
B, D
Explanation:
A self join is a regular join, but the table is joined with itself. This kind of join can take the form of an
inner join, a left outer join, or even a full outer join depending on the requirement.
A . The join key column must have an index. (Incorrect)
While indexes can improve the performance of joins by reducing the cost of the lookup operations,
they are not a requirement for a self join. A self join can be performed with or without an index on
the join key columns.
B . It can be a left outer join. (Correct)
A self join can indeed be a left outer join. This is useful when you want to include all records from the
'left' side of the join (the table itself), even if the join condition does not find any matching record on
the 'right' side (the table itself again).
Reference: Oracle Database SQL Language Reference, which explains the use of joins, including self
joins (Oracle Database SQL Language Reference, 12c Release 1 (12.1)).
C . It must be a full outer join. (Incorrect)
A self join does not need to be a full outer join; it can be any type of join depending on what the
query needs to accomplish.
D . It can be an inner join. (Correct)
Just like with any two different tables, a self join can be an inner join. This would return only the rows
with matching values in the self join condition.
E . It must be an equijoin. (Incorrect)
Although self joins are often equijoins, meaning the join condition is based on equality, they do not
have to be. Self joins can use other operators such as <, >, <=, >=, !=, etc., depending on the
requirements of the query.
Comments
Question 2
Which three statements are true about dropping and unused columns in an Oracle database?
- A. A primary key column referenced by another column as a foreign key can be dropped if using the CASCADE option.
- B. A DROP COLUMN command can be rolled back.
- C. An UNUSED column's space is remained automatically when the block containing that column is next queried.
- D. An UNUSED column's space is remained automatically when the row containing that column is next queried.
- E. Partition key columns cannot be dropped.
- F. A column that is set to NNUSED still counts towards the limit of 1000 columns per table.
Answer:
B, E, F
Explanation:
A . A primary key column referenced by another column as a foreign key can be dropped if using the
CASCADE option. (Incorrect)
Primary key columns that are referenced by foreign keys cannot be dropped as it would violate
referential integrity. The CASCADE option does not apply in this context.
B . A DROP COLUMN command can be rolled back. (Correct)
Dropping a column from a table is a transactional operation. If it's not committed, it can be rolled
back.
Reference: Oracle Database SQL Language Reference confirms that the DROP COLUMN operation is
transactional and can be rolled back if it is not committed (Oracle Database SQL Language Reference,
12c Release 1 (12.1)).
C . An UNUSED column's space is remained automatically when the block containing that column is
next queried. (Incorrect)
The space occupied by an UNUSED column is not automatically reclaimed in this way.
D . An UNUSED column's space is remained automatically when the row containing that column is
next queried. (Incorrect)
Similar to C, the space for an UNUSED column is not reclaimed automatically upon querying the row.
E . Partition key columns cannot be dropped. (Correct)
Partition key columns are integral to the partitioning strategy of a table and cannot be dropped.
Reference: Oracle Database VLDB and Partitioning Guide details the restrictions on dropping partition
key columns (Oracle Database VLDB and Partitioning Guide, 12c Release 1 (12.1)).
F . A column that is set to UNUSED still counts towards the limit of 1000 columns per table. (Correct)
Marking a column as UNUSED is a logical operation that prevents it from being used in future DML
operations, but it still counts towards the column limit of the table until it is actually dropped from
the table.
Reference: Oracle Database SQL Language Reference indicates that UNUSED columns count toward
the column limit (Oracle Database SQL Language Reference, 12c Release 1 (12.1)).
Comments
Question 3
Examine this query:
SELECT TRUNC (ROUND(156.00,-2),-1) FROM DUAL; What is the result?
- A. 16
- B. 160
- C. 150
- D. 200
- E. 100
Answer:
D
Explanation:
The query uses two functions: ROUND and TRUNC. The ROUND function will round the number
156.00 to the nearest hundred because of the -2 which specifies the number of decimal places to
round to. This will result in 200. Then the TRUNC function truncates this number to the nearest 10,
due to the -1 argument, which will give us 200 as the result since truncation does not change the
rounded value in this case.
A . 16 (Incorrect)
B . 160 (Incorrect)
C . 150 (Incorrect)
D . 200 (Incorrect)
E . 100 (Incorrect)
Reference: Oracle Database SQL Language Reference specifies how ROUND and TRUNC functions
behave when applied to numbers (Oracle Database SQL Language Reference, 12c Release 1 (12.1)).
The query functions sequentially: ROUND(156.00,-2) rounds to the nearest hundred, resulting in 200.
Then TRUNC(200,-1) truncates to the nearest ten, which does not change the value, hence the final
result is 200.
Comments
Question 4
Examine this SQL statement:
Which two are true?
- A. The subquery is executed before the UPDATE statement is executed.
- B. All existing rows in the ORDERS table are updated.
- C. The subquery is executed for every updated row in the ORDERS table.
- D. The UPDATE statement executes successfully even if the subquery selects multiple rows.
- E. The subquery is not a correlated subquery.
Answer:
C, A
Explanation:
The provided SQL statement is an update statement that involves a subquery which is correlated to
the main query.
A . The subquery is executed before the UPDATE statement is executed. (Incorrect)
This statement is not accurate in the context of correlated subqueries. A correlated subquery is one
where the subquery depends on values from the outer query. In this case, the subquery is executed
once for each row that is potentially updated by the outer UPDATE statement because it references a
column from the outer query (o.customer_id).
B . All existing rows in the ORDERS table are updated. (Incorrect)
Without a WHERE clause in the outer UPDATE statement, this would typically be true. However, the
correctness of this statement depends on the actual data and presence of matching customer_id
values in both tables. If there are rows in the ORDERS table with customer_id values that do not exist
in the CUSTOMERS table, those rows will not be updated.
C . The subquery is executed for every updated row in the ORDERS table. (Correct)
Because the subquery is correlated (references o.customer_id from the outer query), it must be
executed for each row to be updated in the ORDERS table to get the corresponding cust_last_name
from the CUSTOMERS table.
Reference: The behavior of correlated subqueries is detailed in the Oracle Database SQL Language
Reference, which explains that a correlated subquery is evaluated once for each row processed by
the parent statement (Oracle Database SQL Language Reference, 12c Release 1 (12.1)).
D . The UPDATE statement executes successfully even if the subquery selects multiple rows.
(Incorrect)
The subquery inside the SET clause must return exactly one value for each row to be updated. If the
subquery returns more than one row for any outer row, the UPDATE statement will result in an error
(specifically, an "ORA-01427: single-row subquery returns more than one row" error).
E . The subquery is not a correlated subquery. (Incorrect)
This is incorrect because the subquery references the o.customer_id column from the ORDERS table,
which makes it a correlated subquery.
The correct answers are A and C. The subquery is a correlated subquery because it references the
ORDERS table's customer_id in its WHERE clause. It is executed for each row to be updated since it
depends on values from the outer query (the o.customer_id). It's important to note that although the
statement A is marked incorrect based on the typical behavior of correlated subqueries, in some
cases, Oracle's optimizer may unnest the subquery and execute it beforehand if it determines that
it's more efficient and the result is the same. However, this doesn't change the nature of the query
being a correlated subquery.
Comments
Question 5
Examine the description of the PRODUCTS table: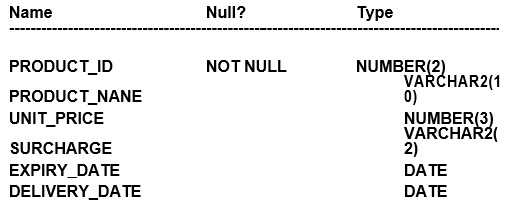
Which three queries use valid expressions?
- A. SELECT produet_id, unit_pricer, 5 "Discount",unit_price+surcharge-discount FROM products;
- B. SELECT product_id, (unit_price * 0.15 / (4.75 + 552.25)) FROM products;
- C. SELECT ptoduct_id, (expiry_date-delivery_date) * 2 FROM products;
- D. SPLECT product_id, expiry_date * 2 FROM products;
- E. SELEGT product_id, unit_price, unit_price + surcharge FROM products;
- F. SELECT product_id,unit_price || "Discount", unit_price + surcharge-discount FROM products;
Answer:
B, C, E
Explanation:
B . SELECT product_id, (unit_price * 0.15 / (4.75 + 552.25)) FROM products; C. SELECT product_id,
(expiry_date - delivery_date) * 2 FROM products; E. SELECT product_id, unit_price, unit_price +
surcharge FROM products;
Comprehensive and Detailed Explanation WITH all Reference:
A . This is invalid because "Discount" is a string literal and cannot be used without quotes in an
arithmetic operation. Also, there is a typo in unit_pricer, and 'discount' is not a defined column in the
table. B. This is valid. It shows a mathematical calculation with unit_price, which is of NUMBER type.
Division and multiplication are valid operations on numbers. C. This is valid. The difference between
two DATE values results in the number of days between them, and multiplying this value by a
number is a valid operation. D. This is invalid because expiry_date is of DATE type and cannot be
multiplied by a number. Also, there's a typo: "SPLECT" should be "SELECT". E. This is valid. Both
unit_price and surcharge are NUMBER types, and adding them together is a valid operation. F. This is
invalid because concatenation operator || is used between a number (unit_price) and a string literal
"Discount", which is not enclosed in single quotes, and 'discount' is not a defined column in the
table.
In SQL, arithmetic operations on numbers and date arithmetic are valid expressions. Concatenation is
also a valid expression when used correctly between string values or literals. Operations that involve
date types should not include multiplication or division by numbers directly without a proper interval
type in Oracle SQL.
These rules are detailed in the Oracle Database SQL Language Reference, where expressions,
datatype precedence, and operations are defined.
Comments
Question 6
Examine this partial command:
Which two clauses are required for this command to execute successfully?
- A. the DEFAULT DIRECTORY clause
- B. the REJECT LIMIT clause
- C. the LOCATION clause
- D. the ACCESS PARAMETERS clause
- E. the access driver TYPE clause
Answer:
C E
Explanation:
In Oracle Database 12c, when creating an external table using the CREATE TABLE ... ORGANIZATION
EXTERNAL statement, there are certain clauses that are mandatory for the command to execute
successfully.
Statement C, the LOCATION clause, is required. The LOCATION clause specifies one or more external
data source locations, typically a file or a directory that the external table will read from. Without
this, Oracle would not know where to find the external data for the table.
Statement E, the access driver TYPE clause, is also required. The access driver tells Oracle how to
interpret the format of the data files. The most common access driver is ORACLE_LOADER, which
allows the reading of data files in a format compatible with the SQL*Loader utility. Another option
could be ORACLE_DATAPUMP, which reads data in a Data Pump format.
Statements A, B, and D are not strictly required for the command to execute successfully, although
they are often used in practice:
A, the DEFAULT DIRECTORY clause, is not mandatory if you have specified the full path in the
LOCATION clause, but it is a best practice to use it to avoid hard-coding directory paths in the
LOCATION clause.
B, the REJECT LIMIT clause, is optional and specifies the maximum number of errors to allow during
the loading of data. If not specified, the default is 0, meaning the load will fail upon the first error
encountered.
D, the ACCESS PARAMETERS clause, is where one would specify parameters for the access driver,
such as field delimiters and record formatting details. While it is common to include this clause to
define the format of the external data, it is not absolutely required for the command to execute;
defaults would be used if this clause is omitted.
For reference, you can find more details in the Oracle Database SQL Language Reference for version
12c, under the CREATE TABLE statement for external tables.
Comments
Question 7
Examine this business rule:
Each student can work on multiple projects and earth project can have multiple students.
You must decide an Entity Relationship (ER) model for optional data storage and allow generating
reports in this format:
STUDENT_ID FIRST_NAME LAST_NAME PROJECT_ID PROJECT_NAME PROJECT_TASK Which two
statements are true?
- A. An associative table must be created with a composite key of STUDENT_ID and PROJECT_ID, which is the foreign key linked to the STUDENTS and PROJECTS entities.
- B. The ER must have a many-to-many relationship between the STUDENTS and PROJECTS entities that must be resolved into 1-to-many relationships.
- C. PROJECT_ID must be the primary key in the PROJECTS entity and foreign key in the STUDENTS entity.
- D. The ER must have a 1-to-many relationship between the STUDENTS and PROJECTS entities.
- E. STUDENT_ID must be the primary key in the STUDENTS entity and foreign key in the PROJECTS entity.
Answer:
A, B
Explanation:
For the described business rule, the relationship between the students and projects entities is a
many-to-many relationship, meaning that each student can be involved in multiple projects and each
project can have multiple students.
Statement A is true because to implement a many-to-many relationship in a relational database, an
associative (junction) table is typically used. This table will contain the primary keys from both
related entities as foreign keys in the associative table, making a composite primary key consisting of
STUDENT_ID and PROJECT_ID. This setup allows the database to effectively manage the relationships
between students and projects.
Statement B is true as it accurately describes the solution to managing a many-to-many relationship.
A direct many-to-many relationship cannot be physically implemented in a relational database. It is
instead resolved into two 1-to-many relationships using an associative table as described in A. This is
a fundamental relational database design principle aimed at normalizing the database and avoiding
redundancy.
Statements C, D, and E are incorrect as they misrepresent the nature of the relationships and key
constraints necessary for this scenario. Specifically, C and E incorrectly suggest that one entity's
primary key should serve as a foreign key in another, which does not align with the many-to-many
relationship requirement described. Statement D incorrectly suggests a 1-to-many relationship
directly between students and projects, which does not meet the business rule requirement.
Comments
Question 8
Which two statements are true about the WHERE and HAVING clauses in a SELECT statement?
- A. The WHERE clause can be used to exclude rows after dividing them into groups
- B. WHERE and HAVING clauses can be used in the same statement only if applied to different table columns.
- C. The HAVING clause can be used with aggregating functions in subqueries.
- D. Aggregating functions and columns used in HAVING clauses must be specified in these SELECT list of a query.
- E. The WHERE clause can be used to exclude rows before dividing them into groups.
Answer:
D, E
Explanation:
In SQL, the WHERE and HAVING clauses are used to filter records; the WHERE clause is applied
before grouping the records, while the HAVING clause is used after grouping the records, particularly
when using aggregation functions.
Statement D is true because the HAVING clause is used to filter groups based on the result of
aggregate functions. Therefore, any column or aggregate function appearing in the HAVING clause
must also appear in the SELECT list of the query, unless it is used as part of an aggregate function.
Statement E is true because the WHERE clause is designed to filter rows before they are grouped into
aggregate groups in a GROUP BY clause. This is a fundamental aspect of SQL that optimizes query
performance by reducing the number of rows to be processed in the aggregate phase.
Statements A, B, and C are incorrect based on the following:
A is incorrect because the WHERE clause does not operate on groups but on individual rows before
grouping.
B is misleading; while WHERE and HAVING can be used in the same statement, their usage is not
restricted to different columns. They perform different functions (row-level filtering vs. group-level
filtering).
C is incorrect because subqueries using aggregate functions typically do not use HAVING clauses;
rather, HAVING is used in the outer query to filter the results of aggregates.
Comments
Question 9
The INVOICE table has a QTY_SOLD column of data type NUMBER and an INVOICE_DATE column of
data type DATE NLS_DATE_FORMAT is set to DD-MON-RR.
Which two are true about data type conversions involving these columns in query expressions?
- A. invoice_date> '01-02-2019': uses implicit conversion
- B. qty_sold ='05549821 ': requires explicit conversion
- C. CONCAT(qty_sold, invoice_date): requires explicit conversion
- D. qty_sold BETWEEN '101' AND '110': uses implicit conversion
- E. invoice_date = '15-march-2019': uses implicit conversion
Answer:
A, E
Explanation:
The statements regarding data type conversions and the treatment of literals in SQL expressions
involve understanding implicit and explicit data conversions in Oracle SQL.
Statement A is true as invoice_date > '01-02-2019' involves an implicit conversion of the string literal
to a date type, based on the NLS_DATE_FORMAT setting, assuming the format matches.
Statement E is true because, similarly to A, invoice_date = '15-march-2019' involves an implicit
conversion where the string is automatically converted to a date type according to the Oracle
NLS_DATE_FORMAT or an assumed default date format.
Statements B, C, and D involve incorrect or misleading information:
B (qty_sold = '05549821') is misleading and potentially incorrect as leading zeros in a numeric
context do not typically require explicit conversion but the presence of spaces might suggest a need
for trimming rather than numeric conversion.
C (CONCAT(qty_sold, invoice_date)) would indeed require explicit conversion because CONCAT
expects string types, and thus numerical and date values must be explicitly converted to strings
before concatenation.
D (qty_sold BETWEEN '101' AND '110') uses implicit conversion where the string literals '101' and
'110' are implicitly converted to numbers if qty_sold is a numeric type.
Comments
Question 10
The PRODUCT_INFORMATION table has a UNIT_PRICE column of data type NUMBER(8, 2).
Evaluate this SQL statement:
SELECT TO_CHAR(unit_price,'$9,999') FROM PRODUCT_INFORMATION;
Which two statements are true about the output?
- A. A row whose UNIT_PRICE column contains the value 1023.99 will be displayed as $1,024.
- B. A row whose UNIT_PRICE column contains the value 1023.99 will be displayed as $1,023.
- C. A row whose UNIT_PRICE column contains the value 10235.99 will be displayed as $1,0236.
- D. A row whose UNIT_PRICE column contains the value 10235.99 will be displayed as $1,023.
- E. A row whose UNIT_PRICE column contains the value 10235.99 will be displayed as #####
Answer:
B, E
Explanation:
The TO_CHAR function is used to convert a number to a string format in Oracle SQL. In this format
mask '$9,999', the dollar sign is a literal, and the 9 placeholders represent a digit in the output. The
comma is a digit group separator.
A . This statement is incorrect because the format model does not have enough digit placeholders to
display the full number 1023.99; it would round it to $1,023 not $1,024. B. This statement is correct.
Given the format '$9,999', the number 1023.99 will be formatted as $1,023 because the format
rounds the number to no decimal places. C. This is incorrect because the format '$9,999' cannot
display the number 10235.99; it exceeds the format's capacity. D. This is incorrect for the same
reason as C, and the format would not change the thousands to hundreds. E. This statement is
correct. If the number exceeds the maximum length of the format mask, which is 4 digits in this case,
Oracle SQL displays a series of hash marks (#) instead of the number.
These formatting rules are described in the Oracle Database SQL Language Reference, which covers
the TO_CHAR function and its number formatting capabilities.
Comments
Page 1 out of 32
Viewing questions 1-10 out of 326
page 2