MuleSoft mcpa-level-1 practice test
MuleSoft Certified Platform Architect - Level 1 Exam
Last exam update: Jul 20 ,2024
Question 1
A company has created a successful enterprise data model (EDM). The company is committed to
building an application network by adopting modern APIs as a core enabler of the company's IT
operating model. At what API tiers (experience, process, system) should the company require reusing
the EDM when designing modern API data models?
- A. At the experience and process tiers
- B. At the experience and system tiers
- C. At the process and system tiers
- D. At the experience, process, and system tiers
Answer:
C
Explanation:
Correct Answer: At the process and system tiers
*****************************************
>> Experience Layer APIs are modeled and designed exclusively for the end user's experience. So, the
data models of experience layer vary based on the nature and type of such API consumer. For
example, Mobile consumers will need light-weight data models to transfer with ease on the wire,
where as web-based consumers will need detailed data models to render most of the info on web
pages, so on. So, enterprise data models fit for the purpose of canonical models but not of good use
for experience APIs.
>> That is why, EDMs should be used extensively in process and system tiers but NOT in experience
tier.
Question 2
Due to a limitation in the backend system, a system API can only handle up to 500 requests per
second. What is the best type of API policy to apply to the system API to avoid overloading the
backend system?
- A. Rate limiting
- B. HTTP caching
- C. Rate limiting - SLA based
- D. Spike control
Answer:
D
Explanation:
Correct Answer: Spike control
*****************************************
>> First things first, HTTP Caching policy is for purposes different than avoiding the backend system
from overloading. So this is OUT.
>> Rate Limiting and Throttling/ Spike Control policies are designed to limit API access, but have
different intentions.
>> Rate limiting protects an API by applying a hard limit on its access.
>> Throttling/ Spike Control shapes API access by smoothing spikes in traffic.
That is why, Spike Control is the right option.
Question 3
A retail company with thousands of stores has an API to receive data about purchases and insert it
into a single database. Each individual store sends a batch of purchase data to the API about every 30
minutes. The API implementation uses a database bulk insert command to submit all the purchase
data to a database using a custom JDBC driver provided by a data analytics solution provider. The API
implementation is deployed to a single CloudHub worker. The JDBC driver processes the data into a
set of several temporary disk files on the CloudHub worker, and then the data is sent to an analytics
engine using a proprietary protocol. This process usually takes less than a few minutes. Sometimes a
request fails. In this case, the logs show a message from the JDBC driver indicating an out-of-file-
space message. When the request is resubmitted, it is successful. What is the best way to try to
resolve this throughput issue?
- A. se a CloudHub autoscaling policy to add CloudHub workers
- B. Use a CloudHub autoscaling policy to increase the size of the CloudHub worker
- C. Increase the size of the CloudHub worker(s)
- D. Increase the number of CloudHub workers
Answer:
D
Explanation:
Correct Answer: Increase the size of the CloudHub worker(s)
*****************************************
The key details that we can take out from the given scenario are:
>> API implementation uses a database bulk insert command to submit all the purchase data to a
database
>> JDBC driver processes the data into a set of several temporary disk files on the CloudHub worker
>> Sometimes a request fails and the logs show a message indicating an out-of-file-space message
Based on above details:
>> Both auto-scaling options does NOT help because we cannot set auto-scaling rules based on error
messages. Auto-scaling rules are kicked-off based on CPU/Memory usages and not due to some
given error or disk space issues.
>> Increasing the number of CloudHub workers also does NOT help here because the reason for the
failure is not due to performance aspects w.r.t CPU or Memory. It is due to disk-space.
>> Moreover, the API is doing bulk insert to submit the received batch data. Which means, all data is
handled by ONE worker only at a time. So, the disk space issue should be tackled on "per worker"
basis. Having multiple workers does not help as the batch may still fail on any worker when disk is
out of space on that particular worker.
Therefore, the right way to deal this issue and resolve this is to increase the vCore size of the worker
so that a new worker with more disk space will be provisioned.
Question 4
An API implementation returns three X-RateLimit-* HTTP response headers to a requesting API
client. What type of information do these response headers indicate to the API client?
- A. The error codes that result from throttling
- B. A correlation ID that should be sent in the next request
- C. The HTTP response size
- D. The remaining capacity allowed by the API implementation
Answer:
D
Explanation:
Correct Answer: The remaining capacity allowed by the API implementation.
*****************************************
>> Reference:
https://docs.mulesoft.com/api-manager/2.x/rate-limiting-and-throttling-sla-based-
policies#response-headers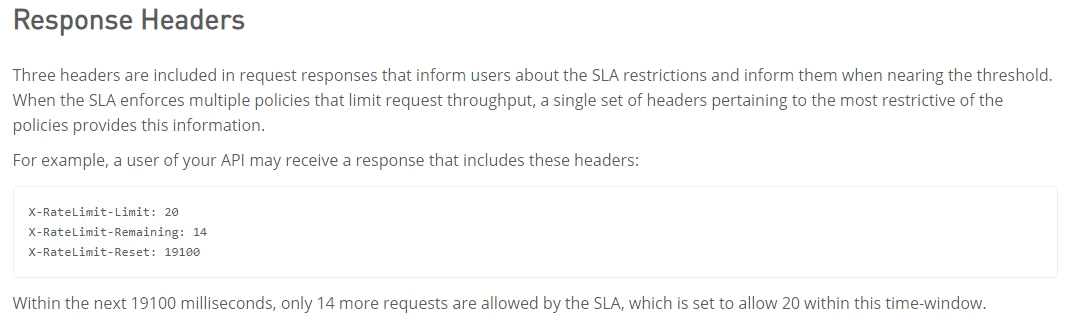
Question 5
An API has been updated in Anypoint exchange by its API producer from version 3.1.1 to 3.2.0
following accepted semantic versioning practices and the changes have been communicated via the
APIs public portal. The API endpoint does NOT change in the new version. How should the developer
of an API client respond to this change?
- A. The API producer should be requested to run the old version in parallel with the new one
- B. The API producer should be contacted to understand the change to existing functionality
- C. The API client code only needs to be changed if it needs to take advantage of the new features
- D. The API clients need to update the code on their side and need to do full regression
Answer:
C
Question 6
A company requires Mule applications deployed to CloudHub to be isolated between non-production
and production environments. This is so Mule applications deployed to non-production
environments can only access backend systems running in their customer-hosted non-production
environment, and so Mule applications deployed to production environments can only access
backend systems running in their customer-hosted production environment. How does MuleSoft
recommend modifying Mule applications, configuring environments, or changing infrastructure to
support this type of per-environment isolation between Mule applications and backend systems?
A.
Modify properties of Mule applications deployed to the production Anypoint Platform environments
to prevent access from non-production Mule applications
B.
Configure firewall rules in the infrastructure inside each customer-hosted environment so that only
IP addresses from the corresponding Anypoint Platform environments are allowed to communicate
with corresponding backend systems
C.
Create non-production and production environments in different Anypoint Platform business groups
D.
Create separate Anypoint VPCs for non-production and production environments, then configure
connections to the backend systems in the corresponding customer-hosted environments
Answer:
D
Explanation:
Correct Answer:Create separate Anypoint VPCs for non-production and production environments,
then configure connections to the backend systems in the corresponding customer-hosted
environments.
*****************************************
>>Creating different Business Groups does NOT make any difference w.r.t accessing the non-prod
and prod customer-hosted environments. Still they will be accessing from both Business Groups
unless process network restrictions are put in place.
>>We need to modify or couple the Mule Application Implementations with the environment. In
fact, we should never implements application coupled with environments by binding them in the
properties. Only basic things like endpoint URL etc should be bundled in properties but not
environment level access restrictions.
>>IP addresses on CloudHub are dynamic until unless a special static addresses are assigned. So it is
not possible to setup firewall rules in customer-hosted infrastrcture. More over, even if static IP
addresses are assigned, there could be 100s of applications running on cloudhub and setting up rules
for all of them would be a hectic task, non-maintainable and definitely got a good practice.
>>Thebest practice recommendedby Mulesoft (In fact any cloud provider), is to have your Anypoint
VPCs seperated for Prod and Non-Prod and perform the VPC peering or VPN tunneling for these
Anypoint VPCs to respective Prod and Non-Prod customer-hosted environment networks.
Reference:
https://docs.mulesoft.com/runtime-manager/virtual-private-cloud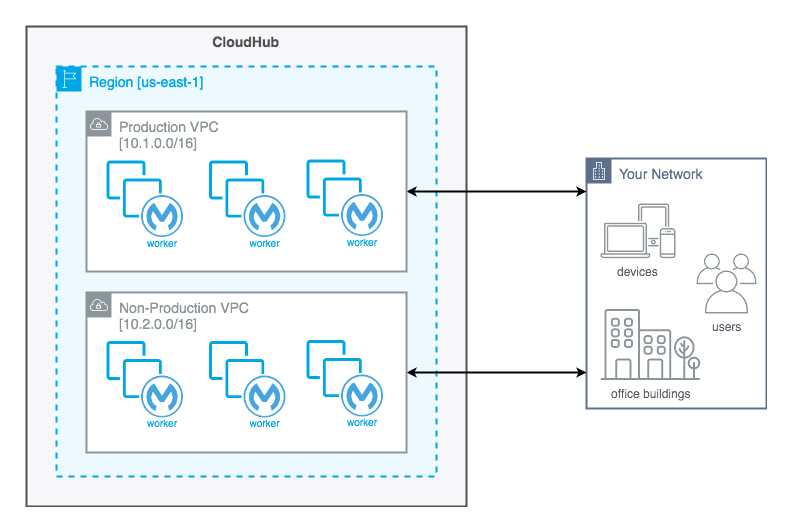
Question 7
An organization wants to make sure only known partners can invoke the organization's APIs. To
achieve this security goal, the organization wants to enforce a Client ID Enforcement policy in API
Manager so that only registered partner applications can invoke the organization's APIs. In what type
of API implementation does MuleSoft recommend adding an API proxy to enforce the Client ID
Enforcement policy, rather than embedding the policy directly in the application's JVM?
- A. A Mule 3 application using APIkit
- B. A Mule 3 or Mule 4 application modified with custom Java code
- C. A Mule 4 application with an API specification
- D. A Non-Mule application
Answer:
D
Explanation:
Correct Answer: A Non-Mule application
*****************************************
>> All type of Mule applications (Mule 3/ Mule 4/ with APIkit/ with Custom Java Code etc) running
on Mule Runtimes support the Embedded Policy Enforcement on them.
>> The only option that cannot have or does not support embedded policy enforcement and must
have API Proxy is for Non-Mule Applications.
So, Non-Mule application is the right answer.
Question 8
A company uses a hybrid Anypoint Platform deployment model that combines the EU control plane
with customer-hosted Mule runtimes. After successfully testing a Mule API implementation in the
Staging environment, the Mule API implementation is set with environment-specific properties and
must be promoted to the Production environment. What is a way that MuleSoft recommends to
configure the Mule API implementation and automate its promotion to the Production environment?
A.
Bundle properties files for each environment into the Mule API implementation's deployable archive,
then promote the Mule API implementation to the Production environment using Anypoint CLI or
the Anypoint Platform REST APIsB.
B.
Modify the Mule API implementation's properties in the API Manager Properties tab, then promote
the Mule API implementation to the Production environment using API Manager
C.
Modify the Mule API implementation's properties in Anypoint Exchange, then promote the Mule API
implementation to the Production environment using Runtime Manager
D.
Use an API policy to change properties in the Mule API implementation deployed to the Staging
environment and another API policy to deploy the Mule API implementation to the Production
environment
Answer:
A
Explanation:
Correct Answer: Bundle properties files for each environment into the Mule API implementation's
deployable archive, then promote the Mule API implementation to the Production environment
using Anypoint CLI or the Anypoint Platform REST APIs
*****************************************
>> Anypoint Exchange is for asset discovery and documentation. It has got no provision to modify the
properties of Mule API implementations at all.
>> API Manager is for managing API instances, their contracts, policies and SLAs. It has also got no
provision to modify the properties of API implementations.
>> API policies are to address Non-functional requirements of APIs and has again got no provision to
modify the properties of API implementations.
So, the right way and recommended way to do this as part of development practice is to bundle
properties files for each environment into the Mule API implementation and just point and refer to
respective file per environment.
Question 9
A system API is deployed to a primary environment as well as to a disaster recovery (DR)
environment, with different DNS names in each environment. A process API is a client to the system
API and is being rate limited by the system API, with different limits in each of the environments. The
system API's DR environment provides only 20% of the rate limiting offered by the primary
environment. What is the best API fault-tolerant invocation strategy to reduce overall errors in the
process API, given these conditions and constraints?
A.
Invoke the system API deployed to the primary environment; add timeout and retry logic to the
process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR
environment
B.
Invoke the system API deployed to the primary environment; add retry logic to the process API to
handle intermittent failures by invoking the system API deployed to the DR environment
C.
In parallel, invoke the system API deployed to the primary environment and the system API deployed
to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures;
add logic to the process API to combine the results
D.
Invoke the system API deployed to the primary environment; add timeout and retry logic to the
process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to
the DR environment
Answer:
A
Explanation:
Correct Answer: Invoke the system API deployed to the primary environment; add timeout and retry
logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed
to the DR environment
*****************************************
There is one important consideration to be noted in the question which is - System API in DR
environment provides only 20% of the rate limiting offered by the primary environment. So,
comparitively, very less calls will be allowed into the DR environment API opposed to its primary
environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation
strategy.
1. Invoking both the system APIs in parallel is definitely NOT a feasible approach because of the 20%
limitation we have on DR environment. Calling in parallel every time would easily and quickly
exhaust the rate limits on DR environment and may not give chance to genuine intermittent error
scenarios to let in during the time of need.
2. Another option given is suggesting to add timeout and retry logic to process API while invoking
primary environment's system API. This is good so far. However, when all retries failed, the option is
suggesting to invoke the copy of process API on DR environment which is not right or recommended.
Only system API is the one to be considered for fallback and not the whole process API. Process APIs
usually have lot of heavy orchestration calling many other APIs which we do not want to repeat again
by calling DR's process API. So this option is NOT right.
3. One more option given is suggesting to add the retry (no timeout) logic to process API to directly
retry on DR environment's system API instead of retrying the primary environment system API first.
This is not at all a proper fallback. A proper fallback should occur only after all retries are performed
and exhausted on Primary environment first. But here, the option is suggesting to directly retry
fallback API on first failure itself without trying main API. So, this option is NOT right too.
This leaves us one option which is right and best fit.
- Invoke the system API deployed to the primary environment
- Add Timeout and Retry logic on it in process API
- If it fails even after all retries, then invoke the system API deployed to the DR environment.
Question 10
In which layer of API-led connectivity, does the business logic orchestration reside?
- A. System Layer
- B. Experience Layer
- C. Process Layer
Answer:
C
Explanation:
Correct Answer: Process Layer
*****************************************
>> Experience layer is dedicated for enrichment of end user experience. This layer is to meet the
needs of different API clients/ consumers.
>> System layer is dedicated to APIs which are modular in nature and implement/ expose various
individual functionalities of backend systems
>> Process layer is the place where simple or complex business orchestration logic is written by
invoking one or many System layer modular APIs
So, Process Layer is the right answer.
Question 11
Once an API Implementation is ready and the API is registered on API Manager, who should request
the access to the API on Anypoint Exchange?
- A. None
- B. Both
- C. API Client
- D. API Consumer
Answer:
D
Explanation:
Correct Answer: API Consumer
*****************************************
>> API clients are piece of code or programs that use the client credentials of API consumer but does
not directly interact with Anypoint Exchange to get the access
>> API consumer is the one who should get registered and request access to API and then API client
needs to use those client credentials to hit the APIs
So, API consumer is the one who needs to request access on the API from Anypoint Exchange
Question 12
Traffic is routed through an API proxy to an API implementation. The API proxy is managed by API
Manager and the API implementation is deployed to a CloudHub VPC using Runtime Manager. API
policies have been applied to this API. In this deployment scenario, at what point are the API policies
enforced on incoming API client requests?
- A. At the API proxy
- B. At the API implementation
- C. At both the API proxy and the API implementation
- D. At a MuleSoft-hosted load balancer
Answer:
A
Explanation:
Correct Answer: At the API proxy
*****************************************
>> API Policies can be enforced at two places in Mule platform.
>> One - As an Embedded Policy enforcement in the same Mule Runtime where API implementation
is running.
>> Two - On an API Proxy sitting in front of the Mule Runtime where API implementation is running.
>> As the deployment scenario in the question has API Proxy involved, the policies will be enforced
at the API Proxy.
Question 13
An API client calls one method from an existing API implementation. The API implementation is later
updated. What change to the API implementation would require the API client's invocation logic to
also be updated?
- A. When the data type of the response is changed for the method called by the API client
- B. When a new method is added to the resource used by the API client
- C. When a new required field is added to the method called by the API client
- D. When a child method is added to the method called by the API client
Answer:
C
Explanation:
Correct Answer: When a new required field is added to the method called by the API client
*****************************************
>> Generally, the logic on API clients need to be updated when the API contract breaks.
>> When a new method or a child method is added to an API , the API client does not break as it can
still continue to use its existing method. So these two options are out.
>> We are left for two more where "datatype of the response if changed" and "a new required field is
added".
>> Changing the datatype of the response does break the API contract. However, the question is
insisting on the "invocation" logic and not about the response handling logic. The API client can still
invoke the API successfully and receive the response but the response will have a different datatype
for some field.
>> Adding a new required field will break the API's invocation contract. When adding a new required
field, the API contract breaks the RAML or API spec agreement that the API client/API consumer and
API provider has between them. So this requires the API client invocation logic to also be updated.
Question 14
An organization has created an API-led architecture that uses various API layers to integrate mobile
clients with a backend system. The backend system consists of a number of specialized components
and can be accessed via a REST API. The process and experience APIs share the same bounded-
context model that is different from the backend data model. What additional canonical models,
bounded-context models, or anti-corruption layers are best added to this architecture to help process
data consumed from the backend system?
- A. Create a bounded-context model for every layer and overlap them when the boundary contexts overlap, letting API developers know about the differences between upstream and downstream data models
- B. Create a canonical model that combines the backend and API-led models to simplify and unify data models, and minimize data transformations.
- C. Create a bounded-context model for the system layer to closely match the backend data model, and add an anti-corruption layer to let the different bounded contexts cooperate across the system and process layers
- D. Create an anti-corruption layer for every API to perform transformation for every data model to match each other, and let data simply travel between APIs to avoid the complexity and overhead of building canonical models
Answer:
C
Explanation:
Correct Answer: Create a bounded-context model for the system layer to closely match the backend
data model, and add an anti-corruption layer to let the different bounded contexts cooperate across
the system and process layers
*****************************************
>> Canonical models are not an option here as the organization has already put in efforts and created
bounded-context models for Experience and Process APIs.
>> Anti-corruption layers for ALL APIs is unnecessary and invalid because it is mentioned that
experience and process APIs share same bounded-context model. It is just the System layer APIs that
need to choose their approach now.
>> So, having an anti-corruption layer just between the process and system layers will work well. Also
to speed up the approach, system APIs can mimic the backend system data model.
Question 15
Which of the following sequence is correct?
- A. API Client implementes logic to call an API >> API Consumer requests access to API >> API Implementation routes the request to >> API
- B. API Consumer requests access to API >> API Client implementes logic to call an API >> API routes the request to >> API Implementation
- C. API Consumer implementes logic to call an API >> API Client requests access to API >> API Implementation routes the request to >> API
- D. API Client implementes logic to call an API >> API Consumer requests access to API >> API routes the request to >> API Implementation
Answer:
B
Explanation:
Correct Answer: API Consumer requests access to API >> API Client implementes logic to call an API
>> API routes the request to >> API Implementation
*****************************************
>> API consumer does not implement any logic to invoke APIs. It is just a role. So, the option stating
"API Consumer implementes logic to call an API" is INVALID.
>> API Implementation does not route any requests. It is a final piece of logic where functionality of
target systems is exposed. So, the requests should be routed to the API implementation by some
other entity. So, the options stating "API Implementation routes the request to >> API" is INVALID
>> The statements in one of the options are correct but sequence is wrong. The sequence is given as
"API Client implementes logic to call an API >> API Consumer requests access to API >> API routes
the request to >> API Implementation". Here, the statements in the options are VALID but sequence
is WRONG.
>> Right option and sequence is the one where API consumer first requests access to API on Anypoint
Exchange and obtains client credentials. API client then writes logic to call an API by using the access
client credentials requested by API consumer and the requests will be routed to API implementation
via the API which is managed by API Manager.