Question 1
An API has been unit tested and is ready for integration testing. The API is governed by a Client ID
Enforcement policy in all environments.
What must the testing team do before they can start integration testing the API in the Staging
environment?
- A. They must access the API portal and create an API notebook using the Client ID and Client Secret supplied by the API portal in the Staging environment
- B. They must request access to the API instance in the Staging environment and obtain a Client ID and Client Secret to be used for testing the API
- C. They must be assigned as an API version owner of the API in the Staging environment
- D. They must request access to the Staging environment and obtain the Client ID and Client Secret for that environment to be used for testing the API
Answer:
B
Explanation:
* It's mentioned that the API is governed by a Client ID Enforcement policy in all environments.
* Client ID Enforcement policy allows only authorized applications to access the deployed API
implementation.
* Each authorized application is configured with credentials: client_id and client_secret.
* At runtime, authorized applications provide the credentials with each request to the API
implementation.
MuleSoft
Reference:
https://docs.mulesoft.com/api-manager/2.x/policy-mule3-client-id-based-
policies
Comments
Question 2
What requires configuration of both a key store and a trust store for an HTTP Listener?
- A. Support for TLS mutual (two-way) authentication with HTTP clients B. Encryption of requests to both subdomains and API resource endpoints fhttPs://aDi.customer.com/ and https://customer.com/api)
- C. Encryption of both HTTP request and HTTP response bodies for all HTTP clients
- D. Encryption of both HTTP request header and HTTP request body for all HTTP clients
Answer:
A
Explanation:
1 way SSL : The server presents its certificate to the client and the client adds it to its list of trusted
certificate. And so, the client can talk to the server.
2-way SSL: The same principle but both ways. i.e. both the client and the server has to establish trust
between themselves using a trusted certificate. In this way of a digital handshake, the server needs
to present a certificate to authenticate itself to client and client has to present its certificate to
server.
* TLS is a cryptographic protocol that provides communications security for your Mule app.
* TLS offers many different ways of exchanging keys for authentication, encrypting data, and
guaranteeing message integrity Keystores and Truststores Truststore and keystore contents differ
depending on whether they are used for clients or servers:
For servers: the truststore contains certificates of the trusted clients, the keystore contains the
private and public key of the server. For clients: the truststore contains certificates of the trusted
servers, the keystore contains the private and public key of the client.
Adding both a keystore and a truststore to the configuration implements two-way TLS authentication
also known as mutual authentication.
* in this case, correct answer is Support for TLS mutual (two-way) authentication with HTTP clients.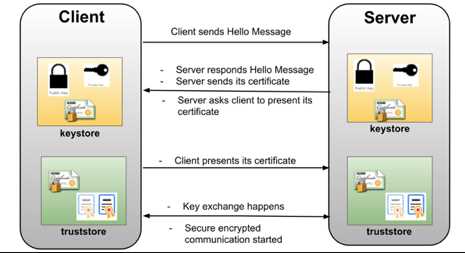
Comments
Question 3
A retailer is designing a data exchange interface to be used by its suppliers. The interface must
support secure communication over the public internet. The interface must also work with a wide
variety of programming languages and IT systems used by suppliers.
What are suitable interface technologies for this data exchange that are secure, cross-platform, and
internet friendly, assuming that Anypoint Connectors exist for these interface technologies?
- A. EDJFACT XML over SFTP JSON/REST over HTTPS
- B. SOAP over HTTPS HOP over TLS gRPC over HTTPS
- C. XML over ActiveMQ XML over SFTP XML/REST over HTTPS
- D. CSV over FTP YAML over TLS JSON over HTTPS
Answer:
C
Explanation:
* As per definition of API by Mulesoft , it is Application Programming Interface using HTTP-based
protocols. Non-HTTP-based programmatic interfaces are not APIs.
* HTTP-based programmatic interfaces are APIs even if they don’t use REST or JSON. Hence
implementation based on Java RMI, CORBA/IIOP, raw TCP/IP interfaces are not API's as they are not
using HTTP.
* One more thing to note is FTP was not built to be secure. It is generally considered to be an
insecure protocol because it relies on clear-text usernames and passwords for authentication and
does not use encryption.
* Data sent via FTP is vulnerable to sniffing, spoofing, and brute force attacks, among other basic
attack methods.
Considering the above points only correct option is
-XML over ActiveMQ
- XML over SFTP
- XML/REST over HTTPS
Comments
Question 4
An organization currently uses a multi-node Mule runtime deployment model within their
datacenter, so each Mule runtime hosts several Mule applications. The organization is planning to
transition to a deployment model based on Docker containers in a Kubernetes cluster. The
organization has already created a standard Docker image containing a Mule runtime and all required
dependencies (including a JVM), but excluding the Mule application itself.
What is an expected outcome of this transition to container-based Mule application deployments?
- A. Required redesign of Mule applications to follow microservice architecture principles
- B. Required migration to the Docker and Kubernetes-based Anypoint Platform - Private Cloud Edition
- C. Required change to the URL endpoints used by clients to send requests to the Mule applications
- D. Guaranteed consistency of execution environments across all deployments of a Mule application
Answer:
A
Explanation:
* Organization can continue using existing load balancer even if backend application changes are
there. So option A is ruled out.
* As Mule runtime is within their datacenter, this model is RTF and not PCE. So option C is ruled out.
Mule runtime deployment model within their datacenter, so each Mule runtime hosts several Mule
applications -- This mean PCE or Hybird not RTF - Also mentioned in Question is that - Mule runtime
is hosting several Mule Application, so that also rules out RTF and as for hosting multiple Application
it will have Domain project which need redesign to make it microservice architecture
---------------------------------------------------------------------------------------------------------------
Correct Answer: Required redesign of Mule applications to follow microservice
Explanation:architecture principles
Comments
Question 5
A team would like to create a project skeleton that developers can use as a starting point when
creating API Implementations with Anypoint Studio. This skeleton should help drive consistent use of
best practices within the team.
What type of Anypoint Exchange artifact(s) should be added to Anypoint Exchange to publish the
project skeleton?
- A. A custom asset with the default API implementation
- B. A RAML archetype and reusable trait definitions to be reused across API implementations
- C. An example of an API implementation following best practices
- D. a Mule application template with the key components and minimal integration logic
Answer:
D
Explanation:
* Sharing Mule applications as templates is a great way to share your work with other people who
are in your organization in Anypoint Platform. When they need to build a similar application they can
create the mule application using the template project from Anypoint studio.
* Anypoint Templates are designed to make it easier and faster to go from a blank canvas to a
production application. They’re bit for bit Mule applications requiring only Anypoint Studio to build
and design, and are deployable both on-premises and in the cloud.
* Anypoint Templates are based on five common data Integration patterns and can be customized
and extended to fit your integration needs. So even if your use case involves different endpoints or
connectors than those included in the template, they still offer a great starting point.
Some of the best practices while creating the template project: - Define the common error handler as
part of template project, either using pom dependency or mule config file - Define common
logger/audit framework as part of the template project - Define the env specific properties and
secure properties file as per the requirement - Define global.xml for global configuration - Define the
config file for connector configuration like Http,Salesforce,File,FTP etc - Create separate folders to
create DWL,Properties,SSL certificates etc - Add the dependency and configure the pom.xml as per
the business need - Configure the mule-artifact.json as per the business need
Comments
Question 6
What aspect of logging is only possible for Mule applications deployed to customer-hosted Mule
runtimes, but NOT for Mule applications deployed to CloudHub?
- A. To send Mule application log entries to Splunk
- B. To change tog4j2 tog levels in Anypoint Runtime Manager without having to restart the Mule application
- C. To log certain messages to a custom log category
- D. To directly reference one shared and customized log4j2.xml file from multiple Mule applications
Answer:
D
Explanation:
* Correct answer is To directly reference one shared and customized log4j2.xml file from multiple
Mule applications. Key word to note in the answer is directly.
* By default, CloudHub replaces a Mule application's log4j2.xml file with a CloudHub log4j2.xml file.
This specifies the CloudHub appender to write logs to the CloudHub logging service.
* You cannot modify CloudHub log4j2.xml file to add any custom appender. But there is a process in
order to achieve this. You need to raise a request on support portal to disable CloudHub provided
Mule application log4j2 file.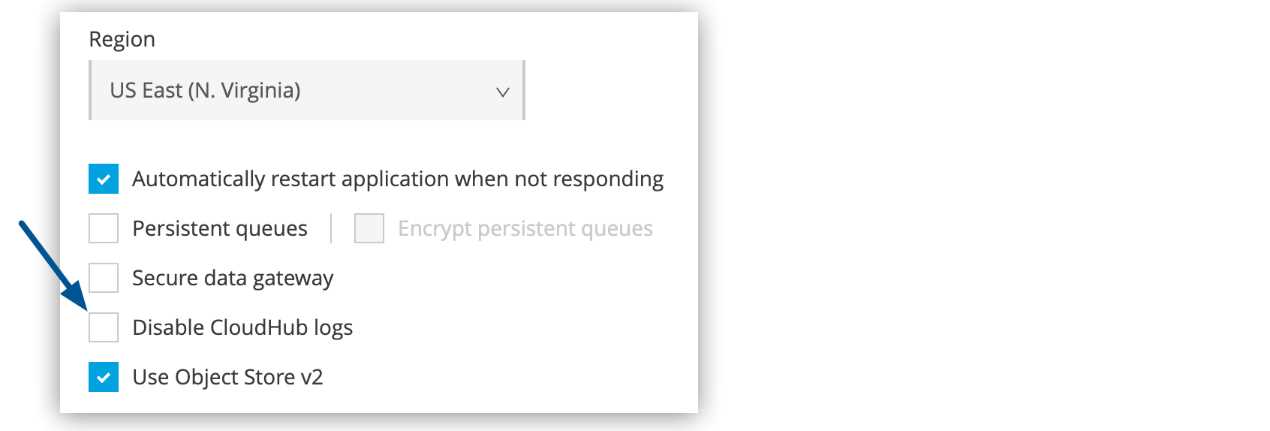
* Once this is done , Mule application's log4j2.xml file is used which you can use to send/export
application logs to other log4j2 appenders, such as a custom logging system MuleSoft does not own
any responsibility for lost logging data due to misconfiguration of your own log4j appender if it
happens by any chance.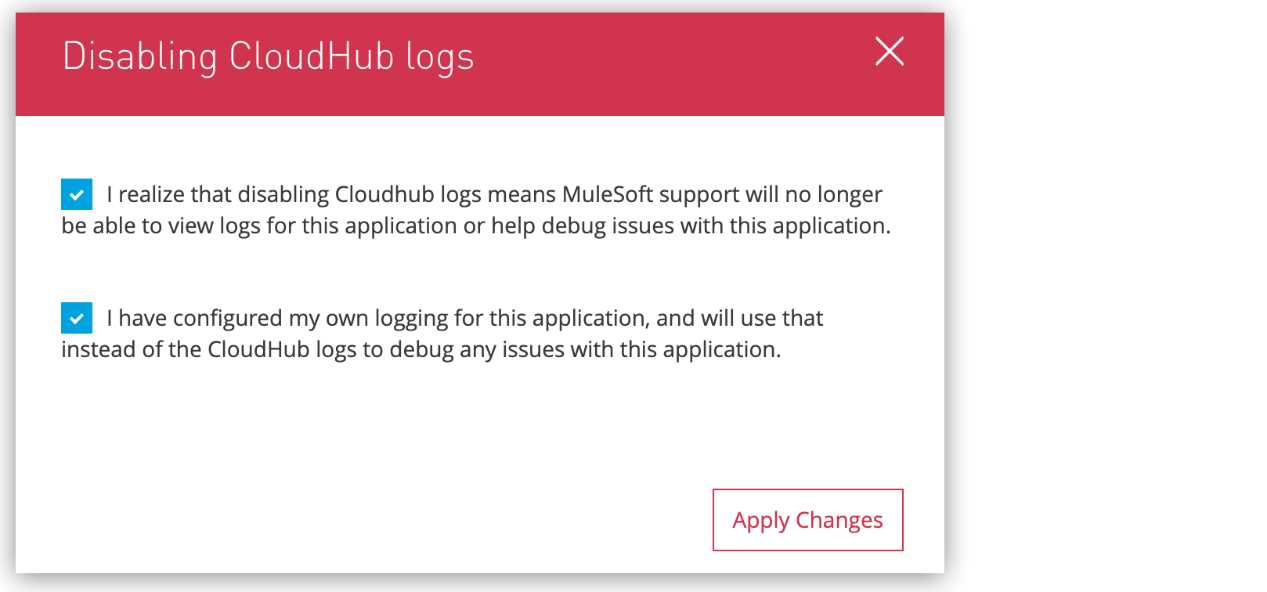
* One more difference between customer-hosted Mule runtimes and CloudHub deployed mule
instance is that
- CloudHub system log messages cannot be sent to external log management system without
installing custom CH logging configuration through support
- where as Customer-hosted runtime can send system and application log to external log
management system
MuleSoft Reference:
https://docs.mulesoft.com/runtime-manager/viewing-log-data
https://docs.mulesoft.com/runtime-manager/custom-log-appender
Comments
Question 7
What is true about the network connections when a Mule application uses a JMS connector to
interact with a JMS provider (message broker)?
- A. To complete sending a JMS message, the JMS connector must establish a network connection with the JMS message recipient
- B. To receive messages into the Mule application, the JMS provider initiates a network connection to the JMS connector and pushes messages along this connection
- C. The JMS connector supports both sending and receiving of JMS messages over the protocol determined by the JMS provider
- D. The AMQP protocol can be used by the JMS connector to portably establish connections to various types of JMS providers
Answer:
C
Explanation:
* To send message or receive JMS (Java Message Service) message no separate network connection
need to be established. So option A, C and D are ruled out.
Correct Answer: The JMS connector supports both sending and receiving of JMS
Explanation:messages over the protocol determined by the JMS provider.
* JMS Connector enables sending and receiving messages to queues and topics for any message
service that implements the JMS specification.
* JMS is a widely used API for message-oriented middleware.
* It enables the communication between different components of a distributed application to be
loosely coupled, reliable, and asynchronous.
MuleSoft Doc Reference:
https://docs.mulesoft.com/jms-connector/1.7/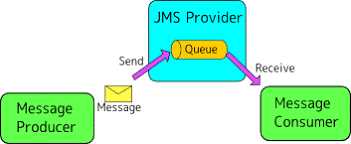
Comments
Question 8
Refer to the exhibit.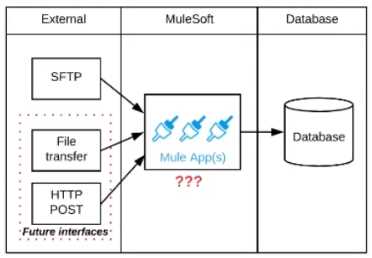
A business process involves the receipt of a file from an external vendor over SFTP. The file needs to
be parsed and its content processed, validated, and ultimately persisted to a database. The delivery
mechanism is expected to change in the future as more vendors send similar files using other
mechanisms such as file transfer or HTTP POST.
What is the most effective way to design for these requirements in order to minimize the impact of
future change?
- A. Use a MuleSoft Scatter-Gather and a MuleSoft Batch Job to handle the different files coming from different sources
- B. Create a Process API to receive the file and process it using a MuleSoft Batch Job while delegating the data save process to a System API
- C. Create an API that receives the file and invokes a Process API with the data contained In the file, then have the Process API process the data using a MuleSoft Batch Job and other System APIs as needed
- D. Use a composite data source so files can be retrieved from various sources and delivered to a MuleSoft Batch Job for processing
Answer:
C
Explanation:
* Scatter-Gather is used for parallel processing, to improve performance. In this scenario, input files
are coming from different vendors so mostly at different times. Goal here is to minimize the impact
of future change. So scatter Gather is not the correct choice.
* If we use 1 API to receive all files from different Vendors, any new vendor addition will need
changes to that 1 API to accommodate new requirements. So Option A and C are also ruled out.
* Correct answer is Create an API that receives the file and invokes a Process API with the data
contained in the file, then have the Process API process the data using a MuleSoft Batch Job and
other System APIs as needed. Answer to this question lies in the API led connectivity approach.
* API-led connectivity is a methodical way to connect data to applications through a series of
reusable and purposeful modern APIs that are each developed to play a specific role – unlock data
from systems, compose data into processes, or deliver an experience. System API : System API tier,
which provides consistent, managed, and secure access to backend systems. Process APIs : Process
APIs take core assets and combines them with some business logic to create a higher level of value.
Experience APIs : These are designed specifically for consumption by a specific end-user app or
device.
So in case of any future plans , organization can only add experience API on addition of new Vendors,
which reuse the already existing process API. It will keep impact minimal.
Comments
Question 9
Refer to the exhibit.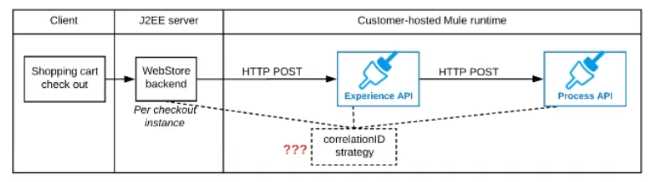
A shopping cart checkout process consists of a web store backend sending a sequence of API
invocations to an Experience API, which in turn invokes a Process API. All API invocations are over
HTTPS POST. The Java web store backend executes in a Java EE application server, while all API
implementations are Mule applications executing in a customer -hosted Mule runtime.
End-to-end correlation of all HTTP requests and responses belonging to each individual checkout
Instance is required. This is to be done through a common correlation ID, so that all log entries
written by the web store backend, Experience API implementation, and Process API implementation
include the same correlation ID for all requests and responses belonging to the same checkout
instance.
What is the most efficient way (using the least amount of custom coding or configuration) for the
web store backend and the implementations of the Experience API and Process API to participate in
end-to-end correlation of the API invocations for each checkout instance?
A)
The web store backend, being a Java EE application, automatically makes use of the thread-local
correlation ID generated by the Java EE application server and automatically transmits that to the
Experience API using HTTP-standard headers
No special code or configuration is included in the web store backend, Experience API, and Process
API implementations to generate and manage the correlation ID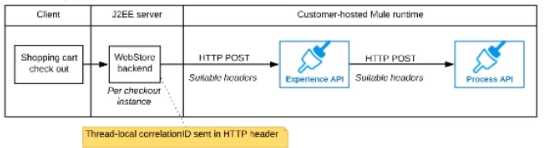
B)
The web store backend generates a new correlation ID value at the start of checkout and sets it on
the X-CORRELATlON-lt HTTP request header In each API invocation belonging to that checkout
No special code or configuration is included in the Experience API and Process API implementations
to generate and manage the correlation ID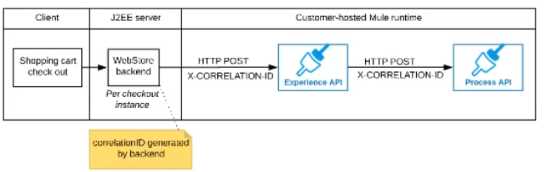
C)
The Experience API implementation generates a correlation ID for each incoming HTTP request and
passes it to the web store backend in the HTTP response, which includes it in all subsequent API
invocations to the Experience API.
The Experience API implementation must be coded to also propagate the correlation ID to the
Process API in a suitable HTTP request header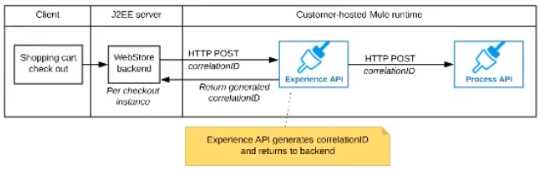
D)
The web store backend sends a correlation ID value in the HTTP request body In the way required by
the Experience API
The Experience API and Process API implementations must be coded to receive the custom
correlation ID In the HTTP requests and propagate It in suitable HTTP request headers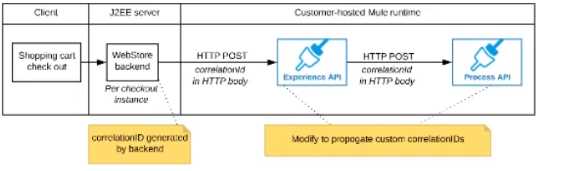
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer:
B
Explanation:
Correct answer is "The web store backend generates a new correlation ID value at the start of
checkout and sets it on the X¬CORRELATION-ID HTTP request header in each API invocation
belonging to that checkout No special code or configuration is included in the Experience API and
Process API implementations to generate and manage the correlation ID" : By design, Correlation Ids
cannot be changed within a flow in Mule 4 applications and can be set only at source. This ID is part
of the Event Context and is generated as soon as the message is received by the application. When a
HTTP Request is received, the request is inspected for "X-Correlation-Id" header. If "X-Correlation-Id"
header is present, HTTP connector uses this as the Correlation Id. If "X-Correlation-Id" header is NOT
present, a Correlation Id is randomly generated. For Incoming HTTP Requests: In order to set a
custom Correlation Id, the client invoking the HTTP request must set "X-Correlation-Id" header. This
will ensure that the Mule Flow uses this Correlation Id. For Outgoing HTTP Requests: You can also
propagate the existing Correlation Id to downstream APIs. By default, all outgoing HTTP Requests
send "X-Correlation-Id" header. However, you can choose to set a different value to "X-Correlation-
Id" header or set "Send Correlation Id" to NEVER.
Mulesoft Reference:
https://help.mulesoft.com/s/article/How-to-Set-Custom-Correlation-Id-for-
Flows-with-HTTP-Endpoint-in-Mule-4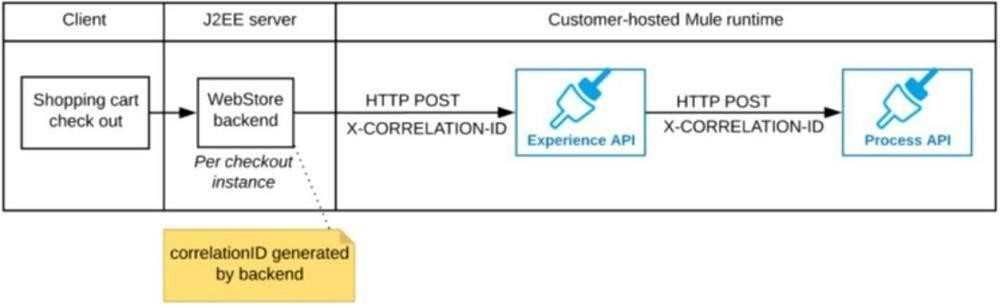
Comments
Question 10
What operation can be performed through a JMX agent enabled in a Mule application?
- A. View object store entries
- B. Replay an unsuccessful message
- C. Set a particular tog4J2 log level to TRACE
- D. Deploy a Mule application
Answer:
C
Explanation:
JMX Management Java Management Extensions (JMX) is a simple and standard way to manage
applications, devices, services, and other resources. JMX is dynamic, so you can use it to monitor and
manage resources as they are created, installed, and implemented. You can also use JMX to monitor
and manage the Java Virtual Machine (JVM). Each resource is instrumented by one or more Managed
Beans, or MBeans. All MBeans are registered in an MBean Server. The JMX server agent consists of
an MBean Server and a set of services for handling Mbeans. There are several agents provided with
Mule for JMX support. The easiest way to configure JMX is to use the default JMX support agent.
Log4J Agent The log4j agent exposes the configuration of the Log4J instance used by Mule for JMX
management. You enable the Log4J agent using the <jmx-log4j> element. It does not take any
additional properties MuleSoft Reference: https://docs.mulesoft.com/mule-runtime/3.9/jmx-
management
Comments
Page 1 out of 24
Viewing questions 1-10 out of 244
page 2