microsoft dp-203 practice test
Data Engineering on Microsoft Azure
Note: Test Case questions are at the end of the exam
Last exam update: Jun 29 ,2025
Question 1 Topic 3, Mixed Questions
You manage an enterprise data warehouse in Azure Synapse Analytics.
Users report slow performance when they run commonly used queries. Users do not report performance changes for
infrequently used queries.
You need to monitor resource utilization to determine the source of the performance issues.
Which metric should you monitor?
- A. DWU percentage
- B. Cache hit percentage
- C. DWU limit
- D. Data IO percentage
Answer:
B
Explanation:
Monitor and troubleshoot slow query performance by determining whether your workload is optimally leveraging the adaptive
cache for dedicated SQL pools.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-how-to-monitor-cache
Question 2 Topic 3, Mixed Questions
You have a SQL pool in Azure Synapse.
A user reports that queries against the pool take longer than expected to complete. You determine that the issue relates to
queried columnstore segments.
You need to add monitoring to the underlying storage to help diagnose the issue.
Which two metrics should you monitor? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Snapshot Storage Size
- B. Cache used percentage
- C. DWU Limit
- D. Cache hit percentage
Answer:
B D
Explanation:
D: Cache hit percentage: (cache hits / cache miss) * 100 where cache hits is the sum of all columnstore segments hits in the
local SSD cache and cache miss is the columnstore segments misses in the local SSD cache summed across all nodes
B: (cache used / cache capacity) * 100 where cache used is the sum of all bytes in the local SSD cache across all nodes and
cache capacity is the sum of the storage capacity of the local SSD cache across all nodes
Incorrect Asnwers:
C: DWU limit: Service level objective of the data warehouse.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-concept-
resource-utilization-query-activity
Question 3 Topic 3, Mixed Questions
A company purchases IoT devices to monitor manufacturing machinery. The company uses an Azure IoT Hub to
communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
- A. Azure Analysis Services using Azure Portal
- B. Azure Analysis Services using Azure PowerShell
- C. Azure Stream Analytics cloud job using Azure Portal
- D. Azure Data Factory instance using Microsoft Visual Studio
Answer:
C
Explanation:
In a real-world scenario, you could have hundreds of these sensors generating events as a stream. Ideally, a gateway device
would run code to push these events to Azure Event Hubs or Azure IoT Hubs. Your Stream Analytics job would ingest these
events from Event Hubs and run real-time analytics queries against the streams.
Create a Stream Analytics job:
In the Azure portal, select + Create a resource from the left navigation menu. Then, select Stream Analytics job from
Analytics.
Reference:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-get-started-with-azure-stream-analytics-to-
process-data-from-iot-devices
Question 4 Topic 3, Mixed Questions
You are designing a star schema for a dataset that contains records of online orders. Each record includes an order date, an
order due date, and an order ship date.
You need to ensure that the design provides the fastest query times of the records when querying for arbitrary date ranges
and aggregating by fiscal calendar attributes.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Create a date dimension table that has a DateTime key.
- B. Use built-in SQL functions to extract date attributes.
- C. Create a date dimension table that has an integer key in the format of YYYYMMDD.
- D. In the fact table, use integer columns for the date fields.
- E. Use DateTime columns for the date fields.
Answer:
B D
Question 5 Topic 3, Mixed Questions
You are designing an inventory updates table in an Azure Synapse Analytics dedicated SQL pool. The table will have a
clustered columnstore index and will include the following columns:
You identify the following usage patterns:
Analysts will most commonly analyze transactions for a warehouse.
Queries will summarize by product category type, date, and/or inventory event type.
You need to recommend a partition strategy for the table to minimize query times.
On which column should you partition the table?
- A. EventTypeID
- B. ProductCategoryTypeID
- C. EventDate
- D. WarehouseID
Answer:
D
Explanation:
The number of records for each warehouse is big enough for a good partitioning.
Note: Table partitions enable you to divide your data into smaller groups of data. In most cases, table partitions are created
on a date column.
When creating partitions on clustered columnstore tables, it is important to consider how many rows belong to each partition.
For optimal compression and performance of clustered columnstore tables, a minimum of 1 million rows per distribution and
partition is needed. Before partitions are created, dedicated SQL pool already divides each table into 60 distributed
databases.
Question 6 Topic 3, Mixed Questions
You are monitoring an Azure Stream Analytics job.
You discover that the Backlogged Input Events metric is increasing slowly and is consistently non-zero.
You need to ensure that the job can handle all the events.
What should you do?
- A. Change the compatibility level of the Stream Analytics job.
- B. Increase the number of streaming units (SUs).
- C. Remove any named consumer groups from the connection and use $default.
- D. Create an additional output stream for the existing input stream.
Answer:
B
Explanation:
Backlogged Input Events: Number of input events that are backlogged. A non-zero value for this metric implies that your job
isn't able to keep up with the number of incoming events. If this value is slowly increasing or consistently non-zero, you
should scale out your job. You should increase the Streaming Units.
Note: Streaming Units (SUs) represents the computing resources that are allocated to execute a Stream Analytics job. The
higher the number of SUs, the more CPU and memory resources are allocated for your job.
Reference:
https://docs.microsoft.com/bs-cyrl-ba/azure/stream-analytics/stream-analytics-monitoring
Question 7 Topic 3, Mixed Questions
You have a SQL pool in Azure Synapse.
You discover that some queries fail or take a long time to complete.
You need to monitor for transactions that have rolled back.
Which dynamic management view should you query?
- A. sys.dm_pdw_request_steps
- B. sys.dm_pdw_nodes_tran_database_transactions
- C. sys.dm_pdw_waits
- D. sys.dm_pdw_exec_sessions
Answer:
B
Explanation:
You can use Dynamic Management Views (DMVs) to monitor your workload including investigating query execution in SQL
pool.
If your queries are failing or taking a long time to proceed, you can check and monitor if you have any transactions rolling
back.
Example:
-- Monitor rollback
SELECT
SUM(CASE WHEN t.database_transaction_next_undo_lsn IS NOT NULL THEN 1 ELSE 0 END), t.pdw_node_id,
nod.[type]
FROM sys.dm_pdw_nodes_tran_database_transactions t
JOIN sys.dm_pdw_nodes nod ON t.pdw_node_id = nod.pdw_node_id GROUP BY t.pdw_node_id, nod.[type]
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-manage-
monitor#monitor-transaction-log-rollback
Question 8 Topic 3, Mixed Questions
HOTSPOT
You need to collect application metrics, streaming query events, and application log messages for an Azure Databrick
cluster.
Which type of library and workspace should you implement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: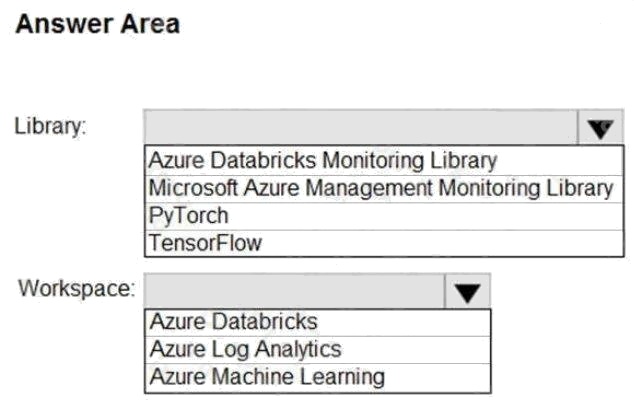
Answer:
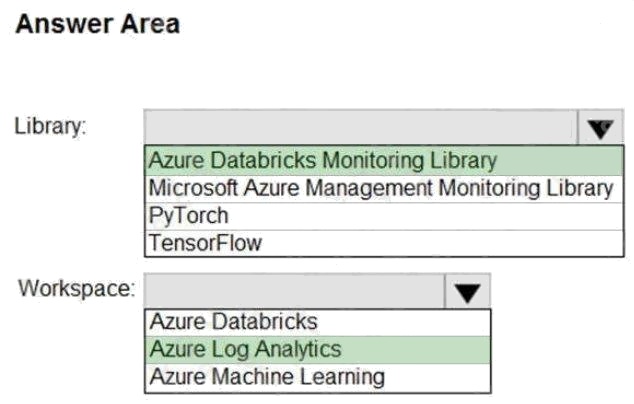
Explanation:
You can send application logs and metrics from Azure Databricks to a Log Analytics workspace. It uses the Azure Databricks
Monitoring Library, which is available on GitHub.
Reference: https://docs.microsoft.com/en-us/azure/architecture/databricks-monitoring/application-logs
Question 9 Topic 3, Mixed Questions
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and a database named DB1. DB1 contains a fact
table named Table1.
You need to identify the extent of the data skew in Table1.
What should you do in Synapse Studio?
- A. Connect to the built-in pool and run DBCC PDW_SHOWSPACEUSED.
- B. Connect to the built-in pool and run DBCC CHECKALLOC.
- C. Connect to Pool1 and query sys.dm_pdw_node_status.
- D. Connect to Pool1 and query sys.dm_pdw_nodes_db_partition_stats.
Answer:
D
Explanation:
Microsoft recommends use of sys.dm_pdw_nodes_db_partition_stats to analyze any skewness in the data.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/cheat-sheet
Question 10 Topic 3, Mixed Questions
You have an Azure data solution that contains an enterprise data warehouse in Azure Synapse Analytics named DW1.
Several users execute ad hoc queries to DW1 concurrently.
You regularly perform automated data loads to DW1.
You need to ensure that the automated data loads have enough memory available to complete quickly and successfully
when the adhoc queries run.
What should you do?
- A. Hash distribute the large fact tables in DW1 before performing the automated data loads.
- B. Assign a smaller resource class to the automated data load queries.
- C. Assign a larger resource class to the automated data load queries.
- D. Create sampled statistics for every column in each table of DW1.
Answer:
C
Explanation:
The performance capacity of a query is determined by the user's resource class. Resource classes are pre-determined
resource limits in Synapse SQL pool that govern compute resources and concurrency for query execution.
Resource classes can help you configure resources for your queries by setting limits on the number of queries that run
concurrently and on the compute-resources assigned to each query. There's a tradeoff between memory and concurrency.
Smaller resource classes reduce the maximum memory per query, but increase concurrency. Larger resource classes
increase the maximum memory per query, but reduce concurrency.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/resource-classes-for-workload-management
Question 11 Topic 3, Mixed Questions
You are designing an Azure Databricks interactive cluster. The cluster will be used infrequently and will be configured for
auto-termination.
You need to use that the cluster configuration is retained indefinitely after the cluster is terminated. The solution must
minimize costs.
What should you do?
- A. Pin the cluster.
- B. Create an Azure runbook that starts the cluster every 90 days.
- C. Terminate the cluster manually when processing completes.
- D. Clone the cluster after it is terminated.
Answer:
A
Explanation:
Azure Databricks retains cluster configuration information for up to 70 all-purpose clusters terminated in the last 30 days and
up to 30 job clusters recently terminated by the job scheduler. To keep an allpurpose cluster configuration even after it has
been terminated for more than 30 days, an administrator can pin a cluster to the cluster list.
Reference:
https://docs.microsoft.com/en-us/azure/databricks/clusters/
Question 12 Topic 3, Mixed Questions
You are monitoring an Azure Stream Analytics job.
The Backlogged Input Events count has been 20 for the last hour.
You need to reduce the Backlogged Input Events count.
What should you do?
- A. Drop late arriving events from the job.
- B. Add an Azure Storage account to the job.
- C. Increase the streaming units for the job.
- D. Stop the job.
Answer:
C
Explanation:
General symptoms of the job hitting system resource limits include:
If the backlog event metric keeps increasing, its an indicator that the system resource is constrained (either because of
output sink throttling, or high CPU).
Note: Backlogged Input Events: Number of input events that are backlogged. A non-zero value for this metric implies that
your job isn't able to keep up with the number of incoming events. If this value is slowly increasing or consistently non-zero,
you should scale out your job: adjust Streaming Units.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-scale-jobs
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-monitoring
Question 13 Topic 3, Mixed Questions
You have an Azure data factory.
You need to examine the pipeline failures from the last 60 days.
What should you use?
- A. the Activity log blade for the Data Factory resource
- B. the Monitor & Manage app in Data Factory
- C. the Resource health blade for the Data Factory resource
- D. Azure Monitor
Answer:
D
Explanation:
Data Factory stores pipeline-run data for only 45 days. Use Azure Monitor if you want to keep that data for a longer time.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/monitor-using-azure-monitor
Question 14 Topic 3, Mixed Questions
You create an Azure Databricks cluster and specify an additional library to install.
When you attempt to load the library to a notebook, the library in not found.
You need to identify the cause of the issue.
What should you review?
- A. notebook logs
- B. cluster event logs
- C. global init scripts logs
- D. workspace logs
Answer:
C
Explanation:
Cluster-scoped Init Scripts: Init scripts are shell scripts that run during the startup of each cluster node before the Spark
driver or worker JVM starts. Databricks customers use init scripts for various purposes such as installing custom libraries,
launching background processes, or applying enterprise security policies.
Logs for Cluster-scoped init scripts are now more consistent with Cluster Log Delivery and can be found in the same root
folder as driver and executor logs for the cluster.
Reference: https://databricks.com/blog/2018/08/30/introducing-cluster-scoped-init-scripts.html
Question 15 Topic 3, Mixed Questions
You have an Azure Synapse Analytics dedicated SQL pool that contains a large fact table. The table contains 50 columns
and 5 billion rows and is a heap.
Most queries against the table aggregate values from approximately 100 million rows and return only two columns.
You discover that the queries against the fact table are very slow.
Which type of index should you add to provide the fastest query times?
- A. nonclustered columnstore
- B. clustered columnstore
- C. nonclustered
- D. clustered
Answer:
B
Explanation:
Clustered columnstore indexes are one of the most efficient ways you can store your data in dedicated SQL pool.
Columnstore tables won't benefit a query unless the table has more than 60 million rows.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/best-practices-dedicated-sql-pool