microsoft ai-102 practice test
Designing and Implementing an Azure AI Solution
Note: Test Case questions are at the end of the exam
Last exam update: Jul 20 ,2024
Question 1 Topic 6, Mixed Questions
DRAG DROP
You are using a Language Understanding service to handle natural language input from the users of a web-based customer
agent. The users report that the agent frequently responds with the following generic response: "Sorry, I don't understand
that."
You need to improve the ability of the agent to respond to requests.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the
answer area and arrange them in the correct order. (Choose three.)
Select and Place:
Answer:

Explanation:
Step 1: Add prebuilt domain models as required.
Prebuilt models provide domains, intents, utterances, and entities. You can start your app with a prebuilt model or add a
relevant model to your app later.
Note: Language Understanding (LUIS) provides prebuilt domains, which are pre-trained models of intents and entities that
work together for domains or common categories of client applications.
The prebuilt domains are trained and ready to add to your LUIS app. The intents and entities of a prebuilt domain are fully
customizable once you've added them to your app.
Step 2: Enable active learning
To enable active learning, you must log user queries. This is accomplished by calling the endpoint query with the log=true
querystring parameter and value.
Step 3: Train and republish the Language Understanding model
The process of reviewing endpoint utterances for correct predictions is called Active learning. Active learning captures
endpoint queries and selects user's endpoint utterances that it is unsure of. You review these utterances to select the intent
and mark entities for these real-world utterances. Accept these changes into your example utterances then train and publish.
LUIS then identifies utterances more accurately.
Incorrect Answers:
Enable log collection by using Log Analytics
Application authors can choose to enable logging on the utterances that are sent to a published application. This is not done
through Log Analytics.
Reference:
https://docs.microsoft.com/en-us/azure/cognitive-services/luis/luis-how-to-review-endpoint-utterances#log-user-queries-to-
enable-active-learning https://docs.microsoft.com/en-us/azure/cognitive-services/luis/luis-concept-prebuilt-model
Question 2 Topic 6, Mixed Questions
You are building a bot on a local computer by using the Microsoft Bot Framework. The bot will use an existing Language
Understanding model.
You need to translate the Language Understanding model locally by using the Bot Framework CLI.
What should you do first?
- A. From the Language Understanding portal, clone the model.
- B. Export the model as an .lu file.
- C. Create a new Speech service.
- D. Create a new Language Understanding service.
Answer:
B
Explanation:
You might want to manage the translation and localization for the language understanding content for your bot
independently.
Translate command in the @microsoft/bf-lu library takes advantage of the Microsoft text translation API to automatically
machine translate .lu files to one or more than 60+ languages supported by the Microsoft text translation cognitive service.
What is translated?
An .lu file and optionally translate
Comments in the lu file
LU reference link texts
List of .lu files under a specific path.
Reference: https://github.com/microsoft/botframework-cli/blob/main/packages/luis/docs/translate-command.md
Question 3 Topic 6, Mixed Questions
DRAG DROP
You plan to build a chatbot to support task tracking.
You create a Language Understanding service named lu1.
You need to build a Language Understanding model to integrate into the chatbot. The solution must minimize development
time to build the model.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the
answer area and arrange them in the correct order. (Choose four.)
Select and Place: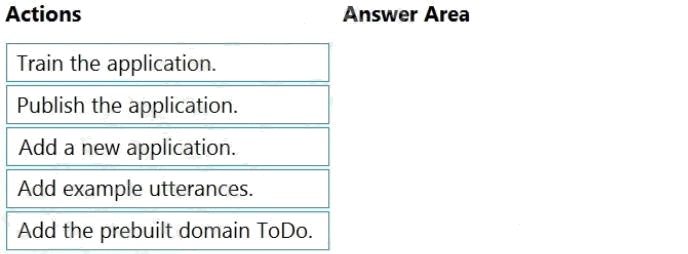
Answer:

Explanation:
Step 1: Add a new application
Create a new app
1. Sign in to the LUIS portal with the URL of https://www.luis.ai.
2. Select Create new app.
3. Etc.
Step 2: Add example utterances.
In order to classify an utterance, the intent needs examples of user utterances that should be classified with this intent.
Step 3: Train the application
Step 4: Publish the application
In order to receive a LUIS prediction in a chat bot or other client application, you need to publish the app to the prediction
endpoint.
Reference:
https://docs.microsoft.com/en-us/azure/cognitive-services/luis/tutorial-intents-only
Question 4 Topic 6, Mixed Questions
You are building a multilingual chatbot.
You need to send a different answer for positive and negative messages.
Which two Text Analytics APIs should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Linked entities from a well-known knowledge base
- B. Sentiment Analysis
- C. Key Phrases
- D. Detect Language
- E. Named Entity Recognition
Answer:
B D
Explanation:
B: The Text Analytics API's Sentiment Analysis feature provides two ways for detecting positive and negative sentiment. If
you send a Sentiment Analysis request, the API will return sentiment labels (such as "negative", "neutral" and "positive") and
confidence scores at the sentence and document-level.
D: The Language Detection feature of the Azure Text Analytics REST API evaluates text input for each document and
returns language identifiers with a score that indicates the strength of the analysis.
This capability is useful for content stores that collect arbitrary text, where language is unknown.
Reference:
https://docs.microsoft.com/en-us/azure/cognitive-services/text-analytics/how-tos/text-analytics-how-to-sentiment-
analysis?tabs=version-3-1 https://docs.microsoft.com/en-us/azure/cognitive-services/text-analytics/how-tos/text-analytics-
how-to-language-detection
Question 5 Topic 6, Mixed Questions
HOTSPOT
You are building a chatbot by using the Microsoft Bot Framework Composer.
You have the dialog design shown in the following exhibit.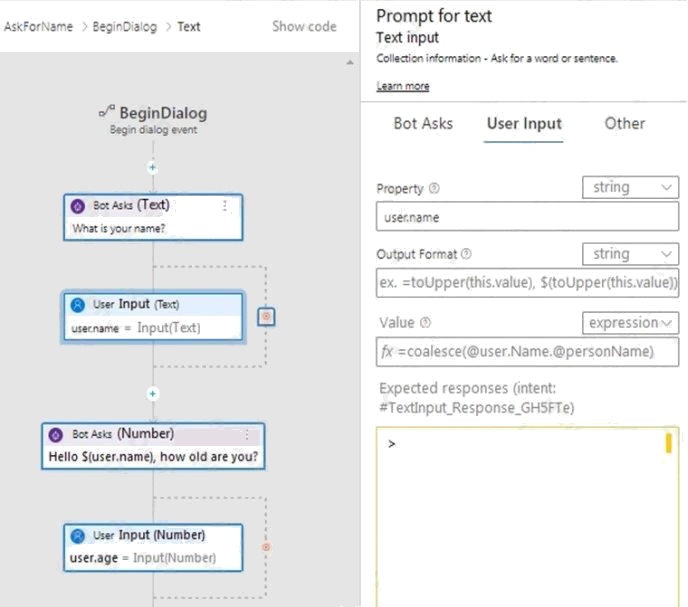
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Explanation:
Box 1: No
User.name is a property.
Box 2: Yes
Box 3: Yes
The coalesce() function evaluates a list of expressions and returns the first non-null (or non-empty for string) expression.
Reference: https://docs.microsoft.com/en-us/composer/concept-language-generation https://docs.microsoft.com/en-
us/azure/data-explorer/kusto/query/coalescefunction
Question 6 Topic 6, Mixed Questions
You build a bot by using the Microsoft Bot Framework SDK and the Azure Bot Service.
You plan to deploy the bot to Azure.
You register the bot by using the Bot Channels Registration service.
Which two values are required to complete the deployment? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. botId
- B. tenantId
- C. appId
- D. objectId
- E. appSecret
Answer:
C E
Explanation:
Reference:
https://github.com/MicrosoftDocs/bot-docs/blob/live/articles/bot-service-quickstart-registration.md
Question 7 Topic 6, Mixed Questions
You are developing the smart e-commerce project.
You need to implement autocompletion as part of the Cognitive Search solution.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Make API queries to the autocomplete endpoint and include suggesterName in the body.
- B. Add a suggester that has the three product name fields as source fields.
- C. Make API queries to the search endpoint and include the product name fields in the searchFields query parameter.
- D. Add a suggester for each of the three product name fields.
- E. Set the searchAnalyzer property for the three product name variants.
- F. Set the analyzer property for the three product name variants. Use the default standard Lucene analyzer ("analyzer": null) or a language analyzer (for example, "analyzer": "en.Microsoft") on the field.
Answer:
C D F
Reference: https://docs.microsoft.com/en-us/azure/search/index-add-suggesters
ANSWER: A B F
Explanation:
Scenario: Support autocompletion and autosuggestion based on all product name variants.
A: Call a suggester-enabled query, in the form of a Suggestion request or Autocomplete request, using an API. API usage is
illustrated in the following call to the Autocomplete REST API.
POST /indexes/myxboxgames/docs/autocomplete?search&api-version=2020-06-30
{
"search": "minecraf",
"suggesterName": "sg"
}
B: In Azure Cognitive Search, typeahead or "search-as-you-type" is enabled through a suggester. A suggester provides a list
of fields that undergo additional tokenization, generating prefix sequences to support matches on partial terms. For example,
a suggester that includes a City field with a value for "Seattle" will have prefix combinations of "sea", "seat", "seatt", and
"seattl" to support typeahead.
F. Use the default standard Lucene analyzer ("analyzer": null) or a language analyzer (for example, "analyzer":
"en.Microsoft") on the field.
Reference: https://docs.microsoft.com/en-us/azure/search/index-add-suggesters
Question 8 Topic 6, Mixed Questions
You are developing an application that will use Azure Cognitive Search for internal documents.
You need to implement document-level filtering for Azure Cognitive Search.
Which three actions should you include in the solution? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Send Azure AD access tokens with the search request.
- B. Retrieve all the groups.
- C. Retrieve the group memberships of the user.
- D. Add allowed groups to each index entry.
- E. Create one index per group.
- F. Supply the groups as a filter for the search requests.
Answer:
C D F
Explanation:
Your documents must include a field specifying which groups have access. This information becomes the filter criteria
against which documents are selected or rejected from the result set returned to the issuer.
D: A query request targets the documents collection of a single index on a search service.
CF: In order to trim documents based on group_ids access, you should issue a search query with a
group_ids/any(g:search.in(g, 'group_id1, group_id2,...')) filter, where 'group_id1, group_id2,...' are the groups to which the
search request issuer belongs.
Reference: https://docs.microsoft.com/en-us/azure/search/search-security-trimming-for-azure-search
Question 9 Topic 6, Mixed Questions
DRAG DROP
You have a web app that uses Azure Cognitive Search.
When reviewing billing for the app, you discover much higher than expected charges. You suspect that the query key is
compromised.
You need to prevent unauthorized access to the search endpoint and ensure that users only have read only access to the
documents collection. The solution must minimize app downtime.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the
answer area and arrange them in the correct order.
Select and Place: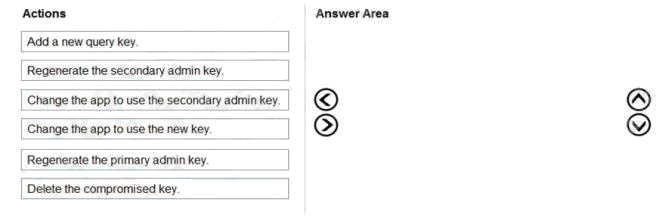
Answer:
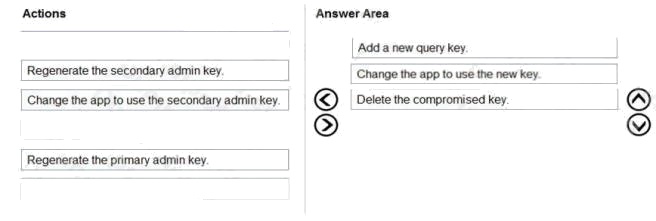
Explanation:
Reference: https://docs.microsoft.com/en-us/azure/search/search-security-api-keys
Question 10 Topic 6, Mixed Questions
You are developing a solution to generate a word cloud based on the reviews of a companys products.
Which Text Analytics REST API endpoint should you use?
- A. keyPhrases
- B. sentiment
- C. languages
- D. entities/recognition/general
Answer:
A
Explanation:
Reference: https://docs.microsoft.com/en-us/azure/cognitive-services/text-analytics/overview
Question 11 Topic 6, Mixed Questions
You have the following data sources:
Finance: On-premises Microsoft SQL Server database
Sales: Azure Cosmos DB using the Core (SQL) API
Logs: Azure Table storage HR: Azure SQL database

You need to ensure that you can search all the data by using the Azure Cognitive Search REST API.
What should you do?
- A. Configure multiple read replicas for the data in Sales.
- B. Mirror Finance to an Azure SQL database.
- C. Ingest the data in Logs into Azure Data Explorer.
- D. Ingest the data in Logs into Azure Sentinel.
Answer:
B
Explanation:
On-premises Microsoft SQL Server database cannot be used as an index data source.
Note: Indexer in Azure Cognitive Search: : Automate aspects of an indexing operation by configuring a data source and an
indexer that you can schedule or run on demand. This feature is supported for a limited number of data source types on
Azure.
Indexers crawl data stores on Azure.
Azure Blob Storage
Azure Data Lake Storage Gen2 (in preview)
Azure Table Storage
Azure Cosmos DB
Azure SQL Database
SQL Managed Instance
SQL Server on Azure Virtual Machines
Reference: https://docs.microsoft.com/en-us/azure/search/search-indexer-overview#supported-data-sources
Question 12 Topic 6, Mixed Questions
HOTSPOT
You are building an Azure Cognitive Search custom skill.
You have the following custom skill schema definition.
For each of the following statements, select Yes if the statement. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Explanation:
Box 1: Yes
Once you have defined a skillset, you must map the output fields of any skill that directly contributes values to a given field in
your search index.
Box 2: Yes
The definition is a custom skill that calls a web API as part of the enrichment process.
Box 3: No
For each organization identified by entity recognition, this skill calls a web API to find the description of that organization.
Reference: https://docs.microsoft.com/en-us/azure/search/cognitive-search-output-field-mapping
Question 13 Topic 6, Mixed Questions
HOTSPOT
You are creating an enrichment pipeline that will use Azure Cognitive Search. The knowledge store contains unstructured
JSON data and scanned PDF documents that contain text.
Which projection type should you use for each data type? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:
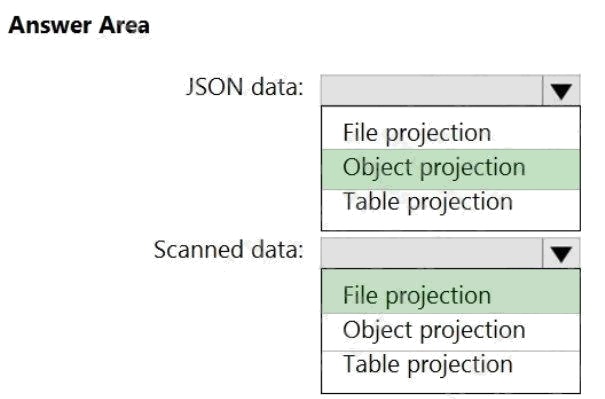
Explanation:
Box 1: Object projection
Object projections are JSON representations of the enrichment tree that can be sourced from any node.
Box 2: File projection
File projections are similar to object projections and only act on the normalized_images collection.
Reference: https://docs.microsoft.com/en-us/azure/search/knowledge-store-projection-overview
Question 14 Topic 6, Mixed Questions
You need to implement a table projection to generate a physical expression of an Azure Cognitive Search index.
Which three properties should you specify in the skillset definition JSON configuration table node? Each correct answer
presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. tableName
- B. generatedKeyName
- C. dataSource
- D. dataSourceConnection
- E. source
Answer:
A B E
Explanation:
Defining a table projection.
Each table requires three properties:
tableName: The name of the table in Azure Storage. generatedKeyName: The column name for the key that uniquely

identifies this row. source: The node from the enrichment tree you are sourcing your enrichments from. This node is
usually the output of a shaper, but could be the output of any of the skills.
Reference: https://docs.microsoft.com/en-us/azure/search/knowledge-store-projection-overview
Question 15 Topic 6, Mixed Questions
You have an existing Azure Cognitive Search service.
You have an Azure Blob storage account that contains millions of scanned documents stored as images and PDFs.
You need to make the scanned documents available to search as quickly as possible.
What should you do?
- A. Split the data into multiple blob containers. Create a Cognitive Search service for each container. Within each indexer definition, schedule the same runtime execution pattern.
- B. Split the data into multiple blob containers. Create an indexer for each container. Increase the search units. Within each indexer definition, schedule a sequential execution pattern.
- C. Create a Cognitive Search service for each type of document.
- D. Split the data into multiple virtual folders. Create an indexer for each folder. Increase the search units. Within each indexer definition, schedule the same runtime execution pattern.
Answer:
D
Explanation:
Incorrect Answers:
A: Need more search units to process the data in parallel.
B: Run them in parallel, not sequentially. C: Need a blob indexer.
Note: A blob indexer is used for ingesting content from Azure Blob storage into a Cognitive Search index.
Index large datasets
Indexing blobs can be a time-consuming process. In cases where you have millions of blobs to index, you can speed up
indexing by partitioning your data and using multiple indexers to process the data in parallel. Here's how you can set this up:
Partition your data into multiple blob containers or virtual folders Set up several data sources, one per container or

folder.
Create a corresponding indexer for each data source. All of the indexers should point to the same target search index.
One search unit in your service can run one indexer at any given time. Creating multiple indexers as described above is
only useful if they actually run in parallel.
Reference: https://docs.microsoft.com/en-us/azure/search/search-howto-indexing-azure-blob-storage