google professional data engineer practice test
Professional Data Engineer on Google Cloud Platform
Last exam update: Jun 26 ,2025
Question 1
You need to copy millions of sensitive patient records from a relational database to BigQuery. The total size of the database
is 10 TB. You need to design a solution that is secure and time-efficient. What should you do?
- A. Export the records from the database as an Avro file. Upload the file to GCS using gsutil, and then load the Avro file into BigQuery using the BigQuery web UI in the GCP Console.
- B. Export the records from the database as an Avro file. Copy the file onto a Transfer Appliance and send it to Google, and then load the Avro file into BigQuery using the BigQuery web UI in the GCP Console.
- C. Export the records from the database into a CSV file. Create a public URL for the CSV file, and then use Storage Transfer Service to move the file to Cloud Storage. Load the CSV file into BigQuery using the BigQuery web UI in the GCP Console.
- D. Export the records from the database as an Avro file. Create a public URL for the Avro file, and then use Storage Transfer Service to move the file to Cloud Storage. Load the Avro file into BigQuery using the BigQuery web UI in the GCP Console.
Answer:
A
Question 2
A shipping company has live package-tracking data that is sent to an Apache Kafka stream in real time. This is then loaded
into BigQuery. Analysts in your company want to query the tracking data in BigQuery to analyze geospatial trends in the
lifecycle of a package. The table was originally created with ingest-date partitioning. Over time, the query processing time
has increased. You need to implement a change that would improve query performance in BigQuery. What should you do?
- A. Implement clustering in BigQuery on the ingest date column.
- B. Implement clustering in BigQuery on the package-tracking ID column.
- C. Tier older data onto Google Cloud Storage files and create a BigQuery table using GCS as an external data source.
- D. Re-create the table using data partitioning on the package delivery date.
Answer:
B
Question 3
You are building a real-time prediction engine that streams files, which may contain PII (personal identifiable information)
data, into Cloud Storage and eventually into BigQuery. You want to ensure that the sensitive data is masked but still
maintains referential integrity, because names and emails are often used as join keys. How should you use the Cloud Data
Loss Prevention API (DLP API) to ensure that the PII data is not accessible by unauthorized individuals?
- A. Create a pseudonym by replacing the PII data with cryptogenic tokens, and store the non-tokenized data in a locked- down button.
- B. Redact all PII data, and store a version of the unredacted data in a locked-down bucket.
- C. Scan every table in BigQuery, and mask the data it finds that has PII.
- D. Create a pseudonym by replacing PII data with a cryptographic format-preserving token.
Answer:
B
Question 4
You are updating the code for a subscriber to a Pub/Sub feed. You are concerned that upon deployment the subscriber may
erroneously acknowledge messages, leading to message loss. Your subscriber is not set up to retain acknowledged
messages. What should you do to ensure that you can recover from errors after deployment?
- A. Set up the Pub/Sub emulator on your local machine. Validate the behavior of your new subscriber logic before deploying it to production.
- B. Create a Pub/Sub snapshot before deploying new subscriber code. Use a Seek operation to re-deliver messages that became available after the snapshot was created.
- C. Use Cloud Build for your deployment. If an error occurs after deployment, use a Seek operation to locate a timestamp logged by Cloud Build at the start of the deployment.
- D. Enable dead-lettering on the Pub/Sub topic to capture messages that arent successfully acknowledged. If an error occurs after deployment, re-deliver any messages captured by the dead-letter queue.
Answer:
C
Explanation:
Reference: https://cloud.google.com/pubsub/docs/replay-overview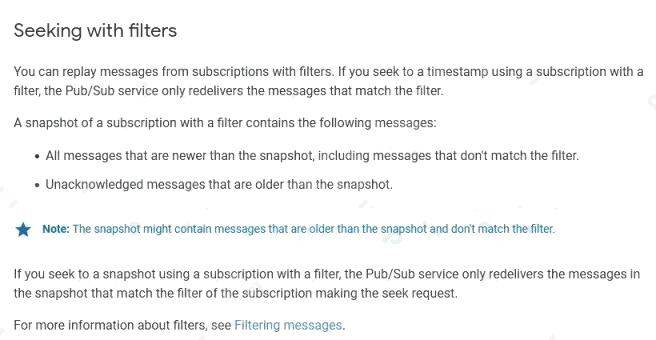
Question 5
You are operating a Cloud Dataflow streaming pipeline. The pipeline aggregates events from a Cloud Pub/Sub subscription
source, within a window, and sinks the resulting aggregation to a Cloud Storage bucket. The source has consistent
throughput. You want to monitor an alert on behavior of the pipeline with Cloud Stackdriver to ensure that it is processing
data. Which Stackdriver alerts should you create?
- A. An alert based on a decrease of subscription/num_undelivered_messages for the source and a rate of change increase of instance/storage/used_bytes for the destination
- B. An alert based on an increase of subscription/num_undelivered_messages for the source and a rate of change decrease of instance/storage/used_bytes for the destination
- C. An alert based on a decrease of instance/storage/used_bytes for the source and a rate of change increase of subscription/num_undelivered_messages for the destination
- D. An alert based on an increase of instance/storage/used_bytes for the source and a rate of change decrease of subscription/num_undelivered_messages for the destination
Answer:
B
Question 6
Your company has a hybrid cloud initiative. You have a complex data pipeline that moves data between cloud provider
services and leverages services from each of the cloud providers. Which cloud-native service should you use to orchestrate
the entire pipeline?
- A. Cloud Dataflow
- B. Cloud Composer
- C. Cloud Dataprep
- D. Cloud Dataproc
Answer:
D
Question 7
You need to choose a database to store time series CPU and memory usage for millions of computers. You need to store
this data in one-second interval samples. Analysts will be performing real-time, ad hoc analytics against the database. You
want to avoid being charged for every query executed and ensure that the schema design will allow for future growth of the
dataset. Which database and data model should you choose?
- A. Create a table in BigQuery, and append the new samples for CPU and memory to the table
- B. Create a wide table in BigQuery, create a column for the sample value at each second, and update the row with the interval for each second
- C. Create a narrow table in Cloud Bigtable with a row key that combines the Computer Engine computer identifier with the sample time at each second
- D. Create a wide table in Cloud Bigtable with a row key that combines the computer identifier with the sample time at each minute, and combine the values for each second as column data.
Answer:
D
Question 8
You decided to use Cloud Datastore to ingest vehicle telemetry data in real time. You want to build a storage system that will
account for the long-term data growth, while keeping the costs low. You also want to create snapshots of the data
periodically, so that you can make a point-in-time (PIT) recovery, or clone a copy of the data for Cloud Datastore in a
different environment. You want to archive these snapshots for a long time. Which two methods can accomplish this?
(Choose two.)
- A. Use managed export, and store the data in a Cloud Storage bucket using Nearline or Coldline class.
- B. Use managed export, and then import to Cloud Datastore in a separate project under a unique namespace reserved for that export.
- C. Use managed export, and then import the data into a BigQuery table created just for that export, and delete temporary export files.
- D. Write an application that uses Cloud Datastore client libraries to read all the entities. Treat each entity as a BigQuery table row via BigQuery streaming insert. Assign an export timestamp for each export, and attach it as an extra column for each row. Make sure that the BigQuery table is partitioned using the export timestamp column.
- E. Write an application that uses Cloud Datastore client libraries to read all the entities. Format the exported data into a JSON file. Apply compression before storing the data in Cloud Source Repositories.
Answer:
C E
Question 9
MJTelco Case Study
Company Overview
MJTelco is a startup that plans to build networks in rapidly growing, underserved markets around the world. The company
has patents for innovative optical communications hardware. Based on these patents, they can create many reliable, high-
speed backbone links with inexpensive hardware.
Company Background
Founded by experienced telecom executives, MJTelco uses technologies originally developed to overcome communications
challenges in space. Fundamental to their operation, they need to create a distributed data infrastructure that drives real-time
analysis and incorporates machine learning to continuously optimize their topologies. Because their hardware is inexpensive,
they plan to overdeploy the network allowing them to account for the impact of dynamic regional politics on location
availability and cost.
Their management and operations teams are situated all around the globe creating many-to-many relationship between data
consumers and provides in their system. After careful consideration, they decided public cloud is the perfect environment to
support their needs.
Solution Concept
MJTelco is running a successful proof-of-concept (PoC) project in its labs. They have two primary needs:
Scale and harden their PoC to support significantly more data flows generated when they ramp to more than 50,000
installations. Refine their machine-learning cycles to verify and improve the dynamic models they use to control topology
definition.
MJTelco will also use three separate operating environments development/test, staging, and production to meet the
needs of running experiments, deploying new features, and serving production customers.
Business Requirements
Scale up their production environment with minimal cost, instantiating resources when and where needed in an
unpredictable, distributed telecom user community. Ensure security of their proprietary data to protect their leading-edge
machine learning and analysis.
Provide reliable and timely access to data for analysis from distributed research workers
Maintain isolated environments that support rapid iteration of their machine-learning models without affecting their
customers.
Technical Requirements
Ensure secure and efficient transport and storage of telemetry data
Rapidly scale instances to support between 10,000 and 100,000 data providers with multiple flows each.
Allow analysis and presentation against data tables tracking up to 2 years of data storing approximately 100m records/day
Support rapid iteration of monitoring infrastructure focused on awareness of data pipeline problems both in telemetry flows
and in production learning cycles.
CEO Statement
Our business model relies on our patents, analytics and dynamic machine learning. Our inexpensive hardware is organized
to be highly reliable, which gives us cost advantages. We need to quickly stabilize our large distributed data pipelines to
meet our reliability and capacity commitments.
CTO Statement
Our public cloud services must operate as advertised. We need resources that scale and keep our data secure. We also
need environments in which our data scientists can carefully study and quickly adapt our models. Because we rely on
automation to process our data, we also need our development and test environments to work as we iterate.
CFO Statement
The project is too large for us to maintain the hardware and software required for the data and analysis. Also, we cannot
afford to staff an operations team to monitor so many data feeds, so we will rely on automation and infrastructure. Google
Clouds machine learning will allow our quantitative researchers to work on our high-value problems instead of problems with
our data pipelines.
MJTelco is building a custom interface to share data. They have these requirements:
1. They need to do aggregations over their petabyte-scale datasets.
2. They need to scan specific time range rows with a very fast response time (milliseconds).
Which combination of Google Cloud Platform products should you recommend?
- A. Cloud Datastore and Cloud Bigtable
- B. Cloud Bigtable and Cloud SQL
- C. BigQuery and Cloud Bigtable
- D. BigQuery and Cloud Storage
Answer:
C
Question 10
You are deploying 10,000 new Internet of Things devices to collect temperature data in your warehouses globally. You need
to process, store and analyze these very large datasets in real time. What should you do?
- A. Send the data to Google Cloud Datastore and then export to BigQuery.
- B. Send the data to Google Cloud Pub/Sub, stream Cloud Pub/Sub to Google Cloud Dataflow, and store the data in Google BigQuery.
- C. Send the data to Cloud Storage and then spin up an Apache Hadoop cluster as needed in Google Cloud Dataproc whenever analysis is required.
- D. Export logs in batch to Google Cloud Storage and then spin up a Google Cloud SQL instance, import the data from Cloud Storage, and run an analysis as needed.
Answer:
B
Question 11
MJTelco Case Study
Company Overview
MJTelco is a startup that plans to build networks in rapidly growing, underserved markets around the world. The company
has patents for innovative optical communications hardware. Based on these patents, they can create many reliable, high-
speed backbone links with inexpensive hardware.
Company Background
Founded by experienced telecom executives, MJTelco uses technologies originally developed to overcome communications
challenges in space. Fundamental to their operation, they need to create a distributed data infrastructure that drives real-time
analysis and incorporates machine learning to continuously optimize their topologies. Because their hardware is inexpensive,
they plan to overdeploy the network allowing them to account for the impact of dynamic regional politics on location
availability and cost.
Their management and operations teams are situated all around the globe creating many-to-many relationship between data
consumers and provides in their system. After careful consideration, they decided public cloud is the perfect environment to
support their needs.
Solution Concept
MJTelco is running a successful proof-of-concept (PoC) project in its labs. They have two primary needs:
Scale and harden their PoC to support significantly more data flows generated when they ramp to more than 50,000
installations. Refine their machine-learning cycles to verify and improve the dynamic models they use to control topology
definition.
MJTelco will also use three separate operating environments development/test, staging, and production to meet the
needs of running experiments, deploying new features, and serving production customers.
Business Requirements
Scale up their production environment with minimal cost, instantiating resources when and where needed in an
unpredictable, distributed telecom user community. Ensure security of their proprietary data to protect their leading-edge
machine learning and analysis.
Provide reliable and timely access to data for analysis from distributed research workers
Maintain isolated environments that support rapid iteration of their machine-learning models without affecting their
customers.
Technical Requirements
Ensure secure and efficient transport and storage of telemetry data
Rapidly scale instances to support between 10,000 and 100,000 data providers with multiple flows each.
Allow analysis and presentation against data tables tracking up to 2 years of data storing approximately 100m records/day
Support rapid iteration of monitoring infrastructure focused on awareness of data pipeline problems both in telemetry flows
and in production learning cycles.
CEO Statement
Our business model relies on our patents, analytics and dynamic machine learning. Our inexpensive hardware is organized
to be highly reliable, which gives us cost advantages. We need to quickly stabilize our large distributed data pipelines to
meet our reliability and capacity commitments.
CTO Statement
Our public cloud services must operate as advertised. We need resources that scale and keep our data secure. We also
need environments in which our data scientists can carefully study and quickly adapt our models. Because we rely on
automation to process our data, we also need our development and test environments to work as we iterate.
CFO Statement
The project is too large for us to maintain the hardware and software required for the data and analysis. Also, we cannot
afford to staff an operations team to monitor so many data feeds, so we will rely on automation and infrastructure. Google
Clouds machine learning will allow our quantitative researchers to work on our high-value problems instead of problems with
our data pipelines.
Given the record streams MJTelco is interested in ingesting per day, they are concerned about the cost of Google BigQuery
increasing. MJTelco asks you to provide a design solution. They require a single large data table called tracking_table.
Additionally, they want to minimize the cost of daily queries while performing fine-grained analysis of each days events.
They also want to use streaming ingestion. What should you do?
- A. Create a table called tracking_table and include a DATE column.
- B. Create a partitioned table called tracking_table and include a TIMESTAMP column.
- C. Create sharded tables for each day following the pattern tracking_table_YYYYMMDD.
- D. Create a table called tracking_table with a TIMESTAMP column to represent the day.
Answer:
B
Question 12
Your company built a TensorFlow neutral-network model with a large number of neurons and layers. The model fits well for
the training data. However, when tested against new data, it performs poorly. What method can you employ to address this?
- A. Threading
- B. Serialization
- C. Dropout Methods
- D. Dimensionality Reduction
Answer:
C
Explanation:
Reference: https://medium.com/mlreview/a-simple-deep-learning-model-for-stock-price-prediction-using-tensorflow-
30505541d877
Question 13
Youre using Bigtable for a real-time application, and you have a heavy load that is a mix of read and writes. Youve recently
identified an additional use case and need to perform hourly an analytical job to calculate certain statistics across the whole
database. You need to ensure both the reliability of your production application as well as the analytical workload.
What should you do?
- A. Export Bigtable dump to GCS and run your analytical job on top of the exported files.
- B. Add a second cluster to an existing instance with a multi-cluster routing, use live-traffic app profile for your regular workload and batch-analytics profile for the analytics workload.
- C. Add a second cluster to an existing instance with a single-cluster routing, use live-traffic app profile for your regular workload and batch-analytics profile for the analytics workload.
- D. Increase the size of your existing cluster twice and execute your analytics workload on your new resized cluster.
Answer:
B
Question 14
Your companys customer and order databases are often under heavy load. This makes performing analytics against them
difficult without harming operations. The databases are in a MySQL cluster, with nightly backups taken using mysqldump.
You want to perform analytics with minimal impact on operations. What should you do?
- A. Add a node to the MySQL cluster and build an OLAP cube there.
- B. Use an ETL tool to load the data from MySQL into Google BigQuery.
- C. Connect an on-premises Apache Hadoop cluster to MySQL and perform ETL.
- D. Mount the backups to Google Cloud SQL, and then process the data using Google Cloud Dataproc.
Answer:
C
Question 15
You are implementing security best practices on your data pipeline. Currently, you are manually executing jobs as the
Project Owner. You want to automate these jobs by taking nightly batch files containing non-public information from Google
Cloud Storage, processing them with a Spark Scala job on a Google Cloud Dataproc cluster, and depositing the results into
Google BigQuery.
How should you securely run this workload?
- A. Restrict the Google Cloud Storage bucket so only you can see the files
- B. Grant the Project Owner role to a service account, and run the job with it
- C. Use a service account with the ability to read the batch files and to write to BigQuery
- D. Use a user account with the Project Viewer role on the Cloud Dataproc cluster to read the batch files and write to BigQuery
Answer:
B