Question 1
A data scientist is utilizing MLflow to track their machine learning experiments. After completing a
series of runs for the experiment with experiment ID exp_id, the data scientist wants to
programmatically work with the experiment run data in a Spark DataFrame. They have an active
MLflow Client client and an active Spark session spark.
Which of the following lines of code can be used to obtain run-level results for exp_id in a Spark
DataFrame?
- A. client.list_run_infos(exp_id)
- B. spark.read.format("delta").load(exp_id)
- C. There is no way to programmatically return row-level results from an MLflow Experiment.
- D. mlflow.search_runs(exp_id)
- E. spark.read.format("mlflow-experiment").load(exp_id)
Answer:
B
Comments
Question 2
A data scientist has developed and logged a scikit-learn random forest model model, and then they
ended their Spark session and terminated their cluster. After starting a new cluster, they want to
review the feature_importances_ of the original model object.
Which of the following lines of code can be used to restore the model object so that
feature_importances_ is available?
- A. mlflow.load_model(model_uri)
- B. client.list_artifacts(run_id)["feature-importances.csv"]
- C. mlflow.sklearn.load_model(model_uri)
- D. This can only be viewed in the MLflow Experiments UI
- E. client.pyfunc.load_model(model_uri)
Answer:
A
Comments
Question 3
Which of the following is a simple statistic to monitor for categorical feature drift?
- A. Mode
- B. None of these
- C. Mode, number of unique values, and percentage of missing values
- D. Percentage of missing values
- E. Number of unique values
Answer:
C
Comments
Question 4
Which of the following is a probable response to identifying drift in a machine learning application?
- A. None of these responses
- B. Retraining and deploying a model on more recent data
- C. All of these responses
- D. Rebuilding the machine learning application with a new label variable
- E. Sunsetting the machine learning application
Answer:
A
Comments
Question 5
A data scientist has computed updated feature values for all primary key values stored in the Feature
Store table features. In addition, feature values for some new primary key values have also been
computed. The updated feature values are stored in the DataFrame features_df. They want to
replace all data in features with the newly computed data.
Which of the following code blocks can they use to perform this task using the Feature Store Client
fs?
A)
B)
C)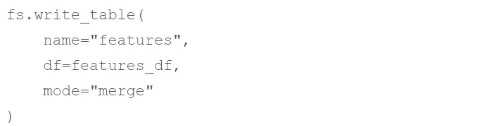
D)
E)
- A. Option A
- B. Option B
- C. Option C
- D. Option D
- E. Option E
Answer:
E
Comments
Question 6
After a data scientist noticed that a column was missing from a production feature set stored as a
Delta table, the machine learning engineering team has been tasked with determining when the
column was dropped from the feature set.
Which of the following SQL commands can be used to accomplish this task?
- A. VERSION
- B. DESCRIBE
- C. HISTORY
- D. DESCRIBE HISTORY
- E. TIMESTAMP
Answer:
D
Comments
Question 7
Which of the following describes label drift?
- A. Label drift is when there is a change in the distribution of the predicted target given by the model
- B. None of these describe label drift
- C. Label drift is when there is a change in the distribution of an input variable
- D. Label drift is when there is a change in the relationship between input variables and target variables
- E. Label drift is when there is a change in the distribution of a target variable
Answer:
C
Comments
Question 8
Which of the following machine learning model deployment paradigms is the most common for
machine learning projects?
- A. On-device
- B. Streaming
- C. Real-time
- D. Batch
- E. None of these deployments
Answer:
B
Comments
Question 9
A data scientist would like to enable MLflow Autologging for all machine learning libraries used in a
notebook. They want to ensure that MLflow Autologging is used no matter what version of the
Databricks Runtime for Machine Learning is used to run the notebook and no matter what
workspace-wide configurations are selected in the Admin Console.
Which of the following lines of code can they use to accomplish this task?
- A. mlflow.sklearn.autolog()
- B. mlflow.spark.autolog()
- C. spark.conf.set(“autologging”, True)
- D. It is not possible to automatically log MLflow runs.
- E. mlflow.autolog()
Answer:
C
Comments
Question 10
A data scientist has developed a model model and computed the RMSE of the model on the test set.
They have assigned this value to the variable rmse. They now want to manually store the RMSE value
with the MLflow run.
They write the following incomplete code block:
Which of the following lines of code can be used to fill in the blank so the code block can successfully
complete the task?
- A. log_artifact
- B. log_model
- C. log_metric
- D. log_param
- E. There is no way to store values like this.
Answer:
A
Comments
Page 1 out of 5
Viewing questions 1-10 out of 60
page 2