amazon AWS Certified Machine Learning Specialty - MLS-C01 practice test
Last exam update: Jun 29 ,2025
Question 1
A manufacturing company uses machine learning (ML) models to detect quality issues. The models use images that are
taken of the company's product at the end of each production step. The company has thousands of machines at the
production site that generate one image per second on average.
The company ran a successful pilot with a single manufacturing machine. For the pilot, ML specialists used an industrial PC
that ran AWS IoT Greengrass with a long-running AWS Lambda function that uploaded the images to Amazon S3. The
uploaded images invoked a Lambda function that was written in Python to perform inference by using an Amazon
SageMaker endpoint that ran a custom model. The inference results were forwarded back to a web service that was hosted
at the production site to prevent faulty products from being shipped.
The company scaled the solution out to all manufacturing machines by installing similarly configured industrial PCs on each
production machine. However, latency for predictions increased beyond acceptable limits. Analysis shows that the internet
connection is at its capacity limit.
How can the company resolve this issue MOST cost-effectively?
- A. Set up a 10 Gbps AWS Direct Connect connection between the production site and the nearest AWS Region. Use the Direct Connect connection to upload the images. Increase the size of the instances and the number of instances that are used by the SageMaker endpoint.
- B. Extend the long-running Lambda function that runs on AWS IoT Greengrass to compress the images and upload the compressed files to Amazon S3. Decompress the files by using a separate Lambda function that invokes the existing Lambda function to run the inference pipeline.
- C. Use auto scaling for SageMaker. Set up an AWS Direct Connect connection between the production site and the nearest AWS Region. Use the Direct Connect connection to upload the images.
- D. Deploy the Lambda function and the ML models onto the AWS IoT Greengrass core that is running on the industrial PCs that are installed on each machine. Extend the long-running Lambda function that runs on AWS IoT Greengrass to invoke the Lambda function with the captured images and run the inference on the edge component that forwards the results directly to the web service.
Answer:
D
Question 2
A retail company is selling products through a global online marketplace. The company wants to use machine learning (ML)
to analyze customer feedback and identify specific areas for improvement. A developer has built a tool that collects customer
reviews from the online marketplace and stores them in an Amazon S3 bucket. This process yields a dataset of 40 reviews.
A data scientist building the ML models must identify additional sources of data to increase the size of the dataset.
Which data sources should the data scientist use to augment the dataset of reviews? (Choose three.)
- A. Emails exchanged by customers and the company’s customer service agents
- B. Social media posts containing the name of the company or its products
- C. A publicly available collection of news articles
- D. A publicly available collection of customer reviews
- E. Product sales revenue figures for the company
- F. Instruction manuals for the company’s products
Answer:
B D F
Question 3
A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a machine learning
specialist will build a binary classifier based on two features: age of account, denoted by x, and transaction month, denoted
by y. The class distributions are illustrated in the provided figure. The positive class is portrayed in red, while the negative
class is portrayed in black.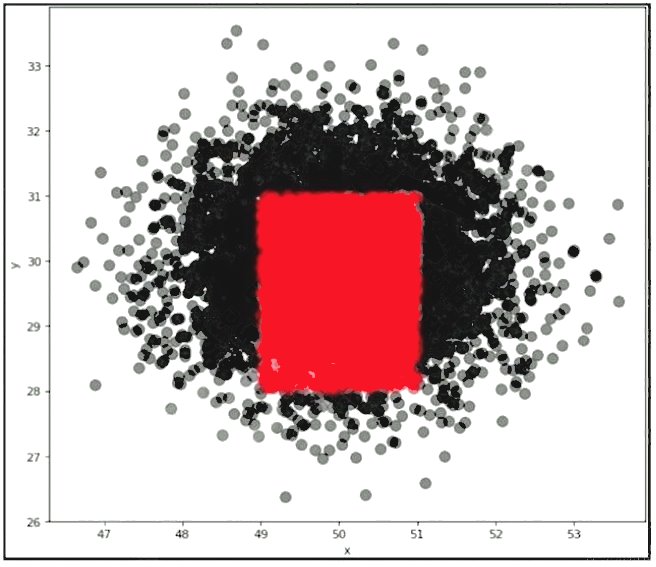
Which model would have the HIGHEST accuracy?
- A. Linear support vector machine (SVM)
- B. Decision tree
- C. Support vector machine (SVM) with a radial basis function kernel
- D. Single perceptron with a Tanh activation function
Answer:
C
Question 4
A Data Scientist needs to create a serverless ingestion and analytics solution for high-velocity, real-time streaming data.
The ingestion process must buffer and convert incoming records from JSON to a query-optimized, columnar format without
data loss. The output datastore must be highly available, and Analysts must be able to run SQL queries against the data and
connect to existing business intelligence dashboards.
Which solution should the Data Scientist build to satisfy the requirements?
- A. Create a schema in the AWS Glue Data Catalog of the incoming data format. Use an Amazon Kinesis Data Firehose delivery stream to stream the data and transform the data to Apache Parquet or ORC format using the AWS Glue Data Catalog before delivering to Amazon S3. Have the Analysts query the data directly from Amazon S3 using Amazon Athena, and connect to BI tools using the Athena Java Database Connectivity (JDBC) connector.
- B. Write each JSON record to a staging location in Amazon S3. Use the S3 Put event to trigger an AWS Lambda function that transforms the data into Apache Parquet or ORC format and writes the data to a processed data location in Amazon S3. Have the Analysts query the data directly from Amazon S3 using Amazon Athena, and connect to BI tools using the Athena Java Database Connectivity (JDBC) connector.
- C. Write each JSON record to a staging location in Amazon S3. Use the S3 Put event to trigger an AWS Lambda function that transforms the data into Apache Parquet or ORC format and inserts it into an Amazon RDS PostgreSQL database. Have the Analysts query and run dashboards from the RDS database.
- D. Use Amazon Kinesis Data Analytics to ingest the streaming data and perform real-time SQL queries to convert the records to Apache Parquet before delivering to Amazon S3. Have the Analysts query the data directly from Amazon S3 using Amazon Athena and connect to BI tools using the Athena Java Database Connectivity (JDBC) connector.
Answer:
A
Question 5
A company wants to predict the sale prices of houses based on available historical sales data. The target variable in the
companys dataset is the sale price. The features include parameters such as the lot size, living area measurements, non-
living area measurements, number of bedrooms, number of bathrooms, year built, and postal code. The company wants to
use multi-variable linear regression to predict house sale prices.
Which step should a machine learning specialist take to remove features that are irrelevant for the analysis and reduce the
models complexity?
- A. Plot a histogram of the features and compute their standard deviation. Remove features with high variance.
- B. Plot a histogram of the features and compute their standard deviation. Remove features with low variance.
- C. Build a heatmap showing the correlation of the dataset against itself. Remove features with low mutual correlation scores.
- D. Run a correlation check of all features against the target variable. Remove features with low target variable correlation scores.
Answer:
D
Question 6
A machine learning specialist stores IoT soil sensor data in Amazon DynamoDB table and stores weather event data as
JSON files in Amazon S3. The dataset in DynamoDB is 10 GB in size and the dataset in Amazon S3 is 5 GB in size. The
specialist wants to train a model on this data to help predict soil moisture levels as a function of weather events using
Amazon SageMaker.
Which solution will accomplish the necessary transformation to train the Amazon SageMaker model with the LEAST amount
of administrative overhead?
- A. Launch an Amazon EMR cluster. Create an Apache Hive external table for the DynamoDB table and S3 data. Join the Hive tables and write the results out to Amazon S3.
- B. Crawl the data using AWS Glue crawlers. Write an AWS Glue ETL job that merges the two tables and writes the output to an Amazon Redshift cluster.
- C. Enable Amazon DynamoDB Streams on the sensor table. Write an AWS Lambda function that consumes the stream and appends the results to the existing weather files in Amazon S3.
- D. Crawl the data using AWS Glue crawlers. Write an AWS Glue ETL job that merges the two tables and writes the output in CSV format to Amazon S3.
Answer:
C
Question 7
A Machine Learning Specialist must build out a process to query a dataset on Amazon S3 using Amazon Athena. The
dataset contains more than 800,000 records stored as plaintext CSV files. Each record contains 200 columns and is
approximately 1.5 MB in size. Most queries will span 5 to 10 columns only.
How should the Machine Learning Specialist transform the dataset to minimize query runtime?
- A. Convert the records to Apache Parquet format.
- B. Convert the records to JSON format.
- C. Convert the records to GZIP CSV format.
- D. Convert the records to XML format.
Answer:
A
Explanation:
Using compressions will reduce the amount of data scanned by Amazon Athena, and also reduce your S3 bucket storage.
Its a Win-Win for your AWS bill. Supported formats: GZIP, LZO, SNAPPY (Parquet) and ZLIB.
Reference: https://www.cloudforecast.io/blog/using-parquet-on-athena-to-save-money-on-aws/
Question 8
When submitting Amazon SageMaker training jobs using one of the built-in algorithms, which common parameters MUST be
specified? (Choose three.)
- A. The training channel identifying the location of training data on an Amazon S3 bucket.
- B. The validation channel identifying the location of validation data on an Amazon S3 bucket.
- C. The IAM role that Amazon SageMaker can assume to perform tasks on behalf of the users.
- D. Hyperparameters in a JSON array as documented for the algorithm used.
- E. The Amazon EC2 instance class specifying whether training will be run using CPU or GPU.
- F. The output path specifying where on an Amazon S3 bucket the trained model will persist.
Answer:
A E F
Question 9
A Machine Learning Specialist is deciding between building a naive Bayesian model or a full Bayesian network for a
classification problem. The Specialist computes the Pearson correlation coefficients between each feature and finds that
their absolute values range between 0.1 to 0.95.
Which model describes the underlying data in this situation?
- A. A naive Bayesian model, since the features are all conditionally independent.
- B. A full Bayesian network, since the features are all conditionally independent.
- C. A naive Bayesian model, since some of the features are statistically dependent.
- D. A full Bayesian network, since some of the features are statistically dependent.
Answer:
C
Question 10
A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a Machine Learning
Specialist would like to build a binary classifier based on two features: age of account and transaction month. The class
distribution for these features is illustrated in the figure provided.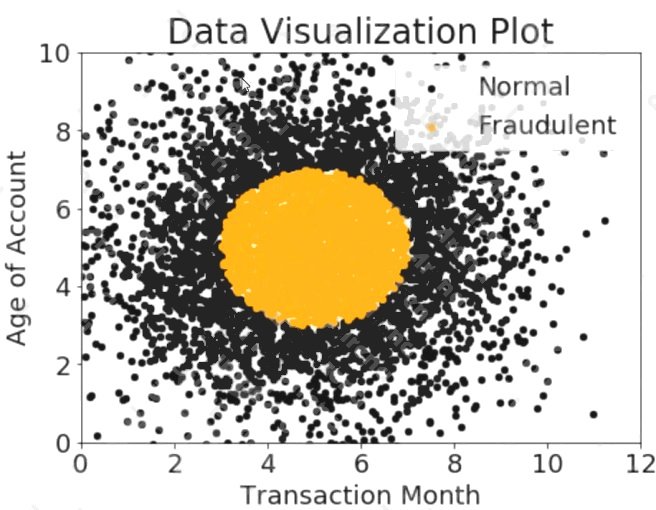
Based on this information, which model would have the HIGHEST recall with respect to the fraudulent class?
- A. Decision tree
- B. Linear support vector machine (SVM)
- C. Naive Bayesian classifier
- D. Single Perceptron with sigmoidal activation function
Answer:
C
Question 11
A real-estate company is launching a new product that predicts the prices of new houses. The historical data for the
properties and prices is stored in .csv format in an Amazon S3 bucket. The data has a header, some categorical fields, and
some missing values. The companys data scientists have used Python with a common open-source library to fill the missing
values with zeros. The data scientists have dropped all of the categorical fields and have trained a model by using the open-
source linear regression algorithm with the default parameters.
The accuracy of the predictions with the current model is below 50%. The company wants to improve the model performance
and launch the new product as soon as possible.
Which solution will meet these requirements with the LEAST operational overhead?
- A. Create a service-linked role for Amazon Elastic Container Service (Amazon ECS) with access to the S3 bucket. Create an ECS cluster that is based on an AWS Deep Learning Containers image. Write the code to perform the feature engineering. Train a logistic regression model for predicting the price, pointing to the bucket with the dataset. Wait for the training job to complete. Perform the inferences.
- B. Create an Amazon SageMaker notebook with a new IAM role that is associated with the notebook. Pull the dataset from the S3 bucket. Explore different combinations of feature engineering transformations, regression algorithms, and hyperparameters. Compare all the results in the notebook, and deploy the most accurate configuration in an endpoint for predictions.
- C. Create an IAM role with access to Amazon S3, Amazon SageMaker, and AWS Lambda. Create a training job with the SageMaker built-in XGBoost model pointing to the bucket with the dataset. Specify the price as the target feature. Wait for the job to complete. Load the model artifact to a Lambda function for inference on prices of new houses.
- D. Create an IAM role for Amazon SageMaker with access to the S3 bucket. Create a SageMaker AutoML job with SageMaker Autopilot pointing to the bucket with the dataset. Specify the price as the target attribute. Wait for the job to complete. Deploy the best model for predictions.
Answer:
A
Explanation:
Reference: https://docs.aws.amazon.com/deep-learning-containers/latest/devguide/deep-learning-containers-ecs-setup.html
Question 12
A Data Scientist is developing a binary classifier to predict whether a patient has a particular disease on a series of test
results. The Data Scientist has data on 400 patients randomly selected from the population. The disease is seen in 3% of the
population.
Which cross-validation strategy should the Data Scientist adopt?
- A. A k-fold cross-validation strategy with k=5
- B. A stratified k-fold cross-validation strategy with k=5
- C. A k-fold cross-validation strategy with k=5 and 3 repeats
- D. An 80/20 stratified split between training and validation
Answer:
B
Question 13
A data scientist is training a text classification model by using the Amazon SageMaker built-in BlazingText algorithm. There
are 5 classes in the dataset, with 300 samples for category A, 292 samples for category B, 240 samples for category C, 258
samples for category D, and 310 samples for category E.
The data scientist shuffles the data and splits off 10% for testing. After training the model, the data scientist generates
confusion matrices for the training and test sets.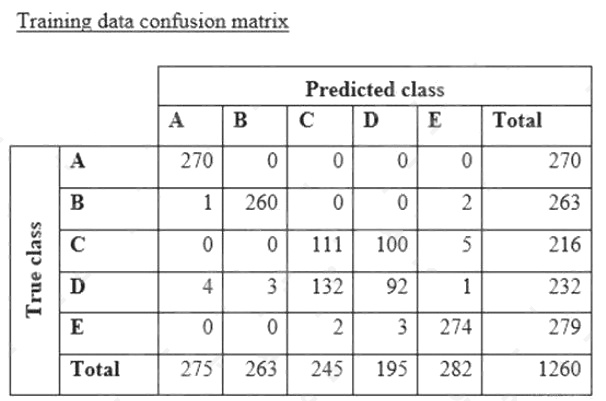
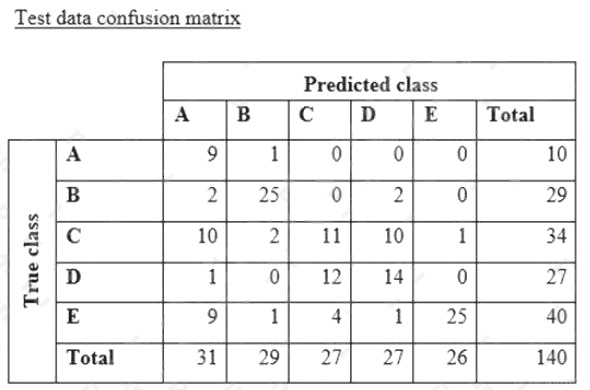
What could the data scientist conclude form these results?
- A. Classes C and D are too similar.
- B. The dataset is too small for holdout cross-validation.
- C. The data distribution is skewed.
- D. The model is overfitting for classes B and E.
Answer:
B
Question 14
A Machine Learning Specialist kicks off a hyperparameter tuning job for a tree-based ensemble model using Amazon
SageMaker with Area Under the ROC Curve (AUC) as the objective metric. This workflow will eventually be deployed in a
pipeline that retrains and tunes hyperparameters each night to model click-through on data that goes stale every 24 hours.
With the goal of decreasing the amount of time it takes to train these models, and ultimately to decrease costs, the Specialist
wants to reconfigure the input hyperparameter range(s).
Which visualization will accomplish this?
- A. A histogram showing whether the most important input feature is Gaussian.
- B. A scatter plot with points colored by target variable that uses t-Distributed Stochastic Neighbor Embedding (t-SNE) to visualize the large number of input variables in an easier-to-read dimension.
- C. A scatter plot showing the performance of the objective metric over each training iteration.
- D. A scatter plot showing the correlation between maximum tree depth and the objective metric.
Answer:
B
Question 15
A gaming company has launched an online game where people can start playing for free, but they need to pay if they
choose to use certain features. The company needs to build an automated system to predict whether or not a new user will
become a paid user within 1 year. The company has gathered a labeled dataset from 1 million users.
The training dataset consists of 1,000 positive samples (from users who ended up paying within 1 year) and 999,000
negative samples (from users who did not use any paid features). Each data sample consists of 200 features including user
age, device, location, and play patterns.
Using this dataset for training, the Data Science team trained a random forest model that converged with over 99% accuracy
on the training set. However, the prediction results on a test dataset were not satisfactory
Which of the following approaches should the Data Science team take to mitigate this issue? (Choose two.)
- A. Add more deep trees to the random forest to enable the model to learn more features.
- B. Include a copy of the samples in the test dataset in the training dataset.
- C. Generate more positive samples by duplicating the positive samples and adding a small amount of noise to the duplicated data.
- D. Change the cost function so that false negatives have a higher impact on the cost value than false positives.
- E. Change the cost function so that false positives have a higher impact on the cost value than false negatives.
Answer:
C D